你不认识的cc++ volatile
Posted 2020-07-24 19:46 +0800 by ZhangJie ‐ 5 min read
1. 令人困惑的volatile
volatile字面意思是“不稳定的、易变的”,不少编程语言中存在volatile关键字,也有共同之处,如“表示程序执行期间数据可能会被外部操作修改”,如被外设修改或者被其他线程修改等。这只是字面上给我们的一般性认识,然而具体到不同的编程语言中volatile的语义可能相差甚远。
很多人以为自己精通CC++,但是被问起volatile的时候却无法清晰、果断地表明态度,那只能说明还是处在“从入门到精通”的路上,如果了解一门语言常见特性的使用、能够写健壮高效的程序就算精通的话,那实在是太藐视“大师”的存在了。从一个volatile关键字折射出了对CC++标准、编译器、操作系统、处理器、MMU各个方面的掌握程度。
几十年的发展,很多开发者因为自己的偏见、误解,或者对某些语言特性(如Java中的volatile语义)的根深蒂固的认识,赋予了CC++ volatile本不属于它的能力,自己却浑然不知自己犯了多大的一个错误。
我曾经以为CC++中volatile可以保证线程可见性,因为Java中是这样的,直到后来阅读Linux内核看到Linus Torvards的一篇文档,他强调了volatile可能带来的坏处“任何使用volatile的地方,都可能潜藏了一个bug”,我为他的“危言耸听”感到吃惊,所以我当时搜索了不少资料来求证CC++ volatile的能力,事后我认为CC++ volatile不能保证线程可见性。但是后来部门内一次分享,分享中提到了volatile来保证线程可见性,我当时心存疑虑,事后验证时犯了一个错误导致我错误地认为volatile可以保证线程可见性。直到我最近翻阅以前的笔记,翻到了几年前对volatile的疑虑……我决定深入研究下这个问题,以便能顺利入眠。
2. 从规范认识volatile
以常见的编程语言C、C++、Java为例,它们都有一个关键字volatile,但是对volatile的定义却并非完全相同。
Java中对volatile的定义:
8.3.1.4.
volatileFieldsThe Java programming language allows threads to access shared variables (§17.1). As a rule, to ensure that shared variables are consistently and reliably updated, a thread should ensure that it has exclusive use of such variables by obtaining a lock that, conventionally, enforces mutual exclusion for those shared variables.
The Java programming language provides a second mechanism,
volatilefields, that is more convenient than locking for some purposes.A field may be declared
volatile, in which case the Java Memory Model ensures that all threads see a consistent value for the variable (§17.4).Java清晰地表达了这样一个观点,Java内存模型中会保证volatile变量的线程可见性,接触过Java并发编程的开发者应该都清楚,这是一个不争的事实。
CC++中对volatile的定义:
6.7.3 Type qualifiers
volatile: No cacheing through this lvalue: each operation in the abstract semantics must be performed (that is, no cacheing assumptions may be made, since the location is not guaranteed to contain any previous value). In the absence of this qualifier, the contents of the designated location may be assumed to be unchanged except for possible aliasing.
C99中也清晰地表名了volatile的语义,不要做cache之类的优化。这里的cache指的是software cacheing,即编译器生成指令将内存数据缓存到cpu寄存器,后续访问内存变量使用寄存器中的值;需要与之作出区分的是hardware cacheing,即cpu访问内存时将内存数据缓存到cpu cache,硬件操作完全对上层应用程序透明。大家请将这两个点铭记在心,要想搞清楚CC++ volatile必须要先理解这里cache的区别。
C99清晰吗?上述解释看上去很清晰,但是要想彻底理解volatile的语义,绝非上述一句话就可以讲得清的,C99中定义了abstract machine以及sequence points,与volatile相关的描述有多处,篇幅原因这里就不一一列举了,其中与volatile相关的abstract machine行为描述共同确定了volatile的语义。
3. 对volatile持何观点
为了引起大家对CC++ volatile的重视并及时表明观点,先贴一个页面“Is-Volatile-Useful-with-Threads”,网站中简明扼要的告知大家,“Friends don’t let friends use volatile for inter-thread communication in C and C++”。But why?

isocpp专门挂了这么个页面来强调volatile在不同编程语言中的差异,可见它是一个多么难缠的问题。即便是有这么个页面,要彻底搞清楚volatile,也不是说读完上面列出的几个技术博客就能解决,那也太轻描淡写了,所以我搜索、整理、讨论,希望能将学到的内容总结下来供其他开发者参考,我也不想再因为这个问题而困扰。
结合CC++ volatile qualifier以及abstract machine中对volatile相关sequence points的描述,可以确定volatile的语义:
- 不可优化性:不要做任何软件cache之类的优化,即多次访问内存对象时,编译器不能优化为cache内存对象到寄存器、后续访问内存对象转为访问寄存器 [6.7.3 Type qualifiers - volatile];
- 顺序性:对volatile变量的多次读写操作,编译器不能以预测数据不变为借口优化掉读写操作,并且要保证前面的读写操作先于后面的读写操作完成 [5.1.2.3 Program execution];
- 易变性:从不可优化性、顺序性语义要求,不难体会出其隐含着数据“易变性”,这也是volatile字面上的意思,也是不少开发者学习volatile时最熟知的语义;
CC++规范没有显示要求volatile支持线程可见性,gcc也没有在标准允许的空间内做什么“发挥”去安插什么保证线程可见性的处理器指令(Java中volatile会使用lock指令使其他处理器cache失效强制读内存保证线程可见性)。而关于CPU cache一致性协议,x86原先采用MESI协议,后改用效率更高的MESIF,都是强一致性协议,在x86这等支持强一致的CPU上,CC++中结合volatile是可以“获得”线程可见性的,在非强一致CPU上则不然。
但是CC++ volatile确实是有价值的,很多地方都要使用它,而且不少场景下似乎没有比它更简单的替代方法,下面首先列举CC++ volatile的通用适用场景,方便大家认识volatile,然后我们再研究为什么CC++ volatile不能保证线程可见性。CC++标准中确实没有说volatile要支持线程可见性,大家可以选择就此打住,但是我怀疑的是gcc在标准允许的空间内是怎么做的?操作系统、MMU、处理器是怎么做的?“标准中没有显示列出”,这样的理由还不足以让我停下探索的脚步。
4. CC++ need volatile
CC++ volatile语义“不可优化型”、“顺序性”、“易变性”,如何直观感受它的价值呢?看C99中给出的适用场景吧。
setjmp、longjmp用于实现函数内、函数间跳转(goto只能在函数内跳转),C Spec规定longjmp之后希望跳到的栈帧中的局部变量的值是最新值,而不是setjmp时的值,考虑编译器可能作出一些优化,将auto变量cache到寄存器中,假如setjmp保存硬件上下文的时候恰巧保存了存有该局部变量值的寄存器信息,等longjmp回来的时候就用了旧值。这违背了C Spec的规定,所以这个时候可以使用volatile来避免编译器优化,满足C Spec!
signal handler用于处理进程捕获到的信号,与setjmp、longjmp类似,进程捕获、处理信号时需要保存当前上下文再去处理信号,信号处理完成再恢复上下文继续执行。信号处理函数中也可能会修改某些共享变量,假如共享变量在收到信号时加载到了寄存器,并且保存硬件上下文时也保存起来了,那么信号处理函数执行完毕返回(可能会修改该变量)恢复上下文后,访问到的还是旧值。因此将信号处理函数中要修改的共享变量声明为volatile是必要的。
设备驱动、Memory-Mapped IO、DMA。 我们先看一个示例,假如不使用volatile,编译器会做什么。编译器生成代码可能会将内存变量sum、i放在寄存器中,循环执行过程中,编译器可能认为这个循环可以直接优化掉,sum直接得到了最终的a[0]+a[1]+…a[N]的值,循环体执行次数大大减少。
sum = 0; for (i=0; i<N; ++i) sum += a[i];这种优化对于面向硬件的程序开发(如设备驱动开发、内存映射IO)来说有点过头了,而且会导致错误的行为。下面的代码使用了volatile qualifer,其他与上述代码基本相同。如果不存在volatile修饰,编译器会认为最终*ttyport的值就是a[N-1],前N-1次赋值都是没必要的,所以直接优化成*ttyport = a[N-1]。但是ttyport是外设的设备端口通过内存映射IO得到的虚拟内存地址,编译器发现存在volatile修饰,便不会对循环体中*ttyport = a[i]进行优化,循环体会执行N次赋值,且保证每次赋值操作都与前一次、后一次赋值存在严格的顺序性保证。
volatile short *ttyport; for (i=0; i<N; ++i) *ttyport = a[i];可能大家会有疑问,volatile只是避免编译器将内存变量存储到寄存器,对cpu cache却束手无策,谁能保证每次对*ttyport的写操作都确定写回内存了呢?这里就涉及到cpu cache policy问题了。
对于外设IO而言,有两种常用方式:
- Memory-Mapped IO,简称MMIO,将设备端口(寄存器)映射到进程地址空间。以x86为例,对映射内存区域的读写操作通过普通的load、store访存指令来完成,处理器通过内存类型范围寄存器(MTRR,Memory Type Range Regsiters)和页面属性表(PAT,Page Attribute Table)对不同的内存范围设置不同的CPU cache policy,内核设置MMIO类型范围的cpu cache策略为uncacheable,其他RAM类型范围的cpu cache策略为write-back!即直接绕过cpu cache读写内存,但实际上并没有物理内存参与,而是将读写操作转发到外设,上述代码中*ttyport = a[i]这个赋值操作绕过CPU cache直达外设。
- Port IO,此时外设端口(寄存器)采用独立编址,而非Memory-Mapped IO这种统一编址方式,需要通过专门的cpu指令来对设备端口进行读写,如x86上采用的是指令in、out来完成设备端口的读写。
而如果是**DMA(Direct Memory Access)**操作模式的话,它绕过cpu直接对内存进行操作,期间不中断cpu执行,DMA操作内存方式上与cpu类似,都会考虑cpu cache一致性问题。假如DMA对内存进行读写操作,总线上也会对事件进行广播,cpu cache也会观测到并采取相应的动作。如DMA对内存进行写操作,cpu cache也会将相同内存地址的cache line设置为invalidate,后续读取时就可以重新从内存加载最新数据;假如DMA进行内存读操作,数据可能从其他cpu cache中直接获取而非从内存中。这种情况下DMA操作的内存区域,对应的内存变量也应该使用volatile修饰,避免编译器优化从寄存器中读到旧值。
以上示例摘自C99规范,通过上述示例、解释,可以体会到volatile的语义特点:“不可优化型、易变性、顺序性”。
下面这个示例摘自网络,也比较容易表现volatile的语义特点:
// 应为 volatile unsigned int *p = .... unsigned int *p = GetMagicAddress(); unsigned int a, b; a = *p; b = *p; *p = a; *p = b;GetMagicAddress()返回一个外设的内存映射IO地址,由于
unsigned int *p指针没有volatile修饰,编译器认为*p中的内容不是“易变的”因此可能会作出如下优化。首先从p读取一个字节到寄存器,然后将其赋值给a,然后认为*p内容不变,就直接将寄存器中内容再赋值给b。写*p的时候认为a == b,写两次没必要就只写了一次。而如果通过volatile对*p进行修饰,则就是另一个结果了,编译器会认为*p中内容是易变的,每次读取操作都不会沿用上次加载到寄存器中的旧值,而内存映射IO内存区域对应的cpu cache模式又是被uncacheable的,所以会保证从内存读取到最新写入的数据,成功连续读取两个字节a、b,也保证按顺序写入两个字节a、b。
相信读到这里大家对CC++ volatile的适用场景有所了解了,它确实是有用的。那接下来我们针对开发者误解很严重的一个问题“volatile能否支持线程可见性”再探索一番,不能!不能!不能!
5. CC++ thread visibility
5.1. 线程可见性问题
多线程编程中经常会通过修改共享变量的方式来通知另一个线程发生了某种状态的变化,希望线程能及时感知到这种变化,因此我们关心“线程可见性问题”。
在对称多处理器架构中(SMP),多处理器、核心通过总线共享相同的内存,但是各个处理器核心有自己的cache,线程执行过程中,一般会将内存数据加载到cache中,也可能会加载到寄存器中,以便实现访问效率的提升,但这也带来了问题,比如我们提到的线程可见性问题。某个线程对共享变量做了修改,线程可能只是修改了寄存器中的值或者cpu cache中的值,修改并不会立即同步回内存。即便同步回内存,运行在其他处理器核心上的线程,访问该共享数据时也不会立即去内存中读取最新的数据,无法感知到共享数据的变化。
5.2. diff volatile in java、cc++
有些编程语言中定义了关键字volatile,如Java、C、C++等,对比下Java volatile和CC++ volatile,差异简直是太大了,我们只讨论线程可见性相关的部分。
Java中语言规范明确指出volatile保证内存可见性,JMM存在“本地内存”的概念,线程对“主存”变量的访问都是先加载到本地内存,后续写操作再同步回主存。volatile可以保证一个线程的写操作对其他线程立即可见,首先是保证volatile变量写操作必须要更新到主存,然后还要保证其他线程volatile变量读取必须从主存中读取。处理器中提供了MFENCE指令来创建一个屏障,可以保证MFENCE之前的操作对后续操作可见,用MFENCE可以实现volatile,但是考虑到AMD处理器中耗时问题以及Intel处理器中流水线问题,JVM从MFENCE修改成了LOCK: ADD 0。
但是在C、C++规范里面没有要求volatile具备线程可见性语义,只要求其保证“不可优化性、顺序性、易变性”。
5.3. how gcc handle volatile
这里做个简单的测试:
#include <stdio.h>
int main() {
// volatile int a = 0;
int a = 0;
while(1) {
a++;
printf("%d\n", a);
}
return 0;
}
不开优化的话,有没有volatile gcc生成的汇编指令基本是一致的,volatile变量读写都是针对内存进行,而非寄存器。开gcc -O2优化时,不加volatile情况下读写操作通过寄存器,加了volatile则通过内存。
1)不加volatile :gcc -g -O2 -o main main.c
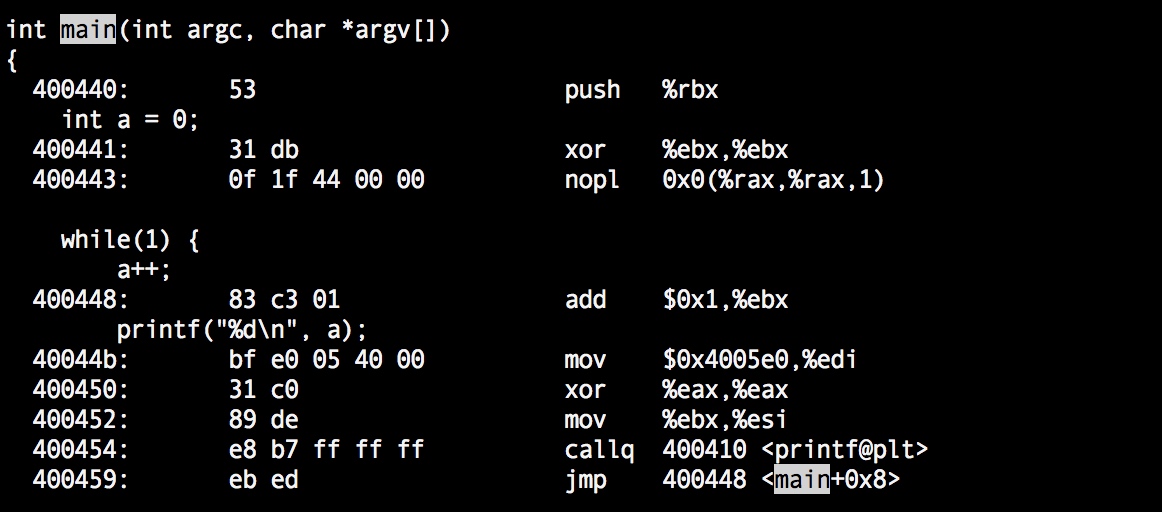
这里重点看下对变量a的操作,xor %ebx,%ebx将寄存器%ebx设为0,也就是将变量a=0存储到了%ebx,nopl不做任何操作,然后循环体里面每次读取a的值都是直接在%ebx+1,加完之后也没有写回内存。假如有个共享变量是多个线程共享的,并且没有加volatile,多个线程访问这个变量的时候就是用的物理线程跑的处理器核心寄存器中的数据,是无法保证内存可见性的。
2)加volatile:gcc -g -O2 -o main main.c
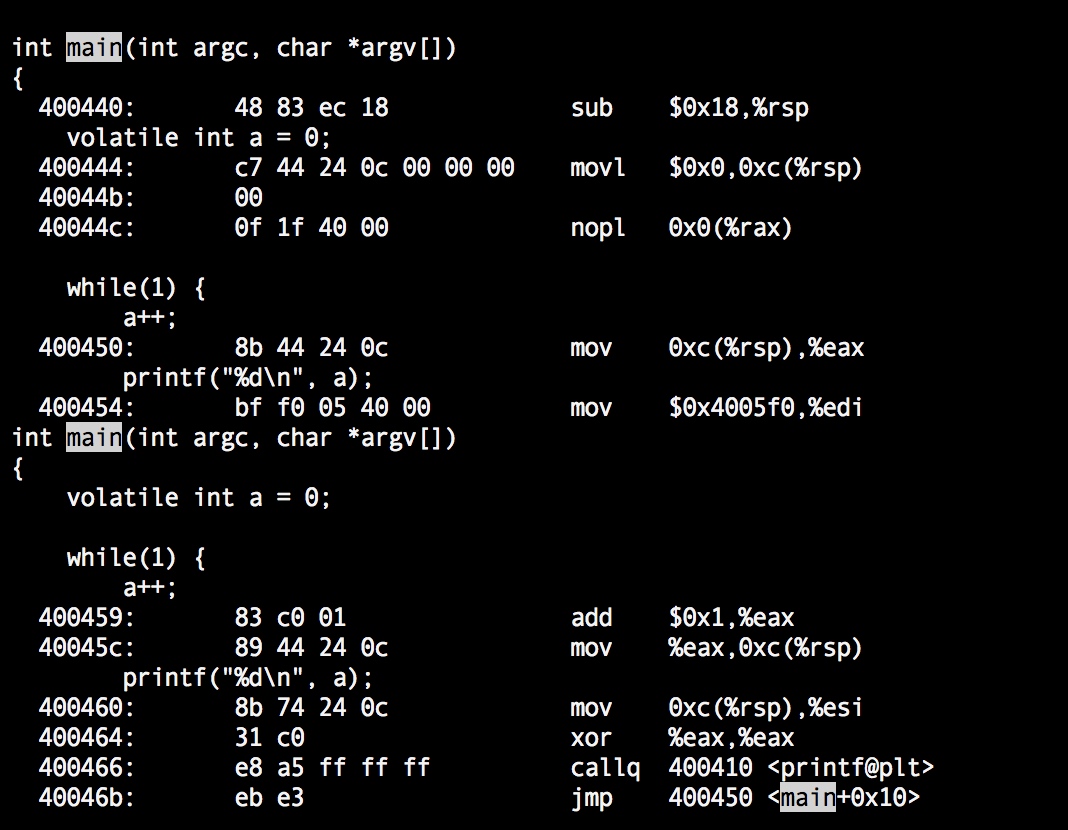
这里变量a的值首先被设置到了0xc(%rsp)中,nopl空操作,然后a++时是将内存中的值移动到了寄存器%eax中,然后执行%eax+1再写回内存0xc(%rsp)中,while循环中每次循环执行都是先从内存里面取值,更新后再写回内存。但是这样就可以保证线程可见性了吗?No!
5.4. how cpu cache works
是否有这样的疑问?CC++中对volatile变量读写,发出的内存读写指令不会被CPU转换成读写CPU cache吗?这个属于硬件层面内容,对上层透明,编译器生成的汇编指令也无法反映实际执行情况!因此,只看上述反汇编示例是不能确定CC++ volatile支持线程可见性的,当然也不能排除这种可能性?
Stack Overflow上Dietmar Kühl提到,‘volatile’阻止了对变量的优化,例如对于频繁访问的变量,会阻止编译器对其进行编译时优化,避免将其放入寄存器中(注意是寄存器而不是cpu的cache)。编译器优化内存访问时,会生成将内存数据缓存到寄存器、后续访问内存操作转换为访问寄存器,这称为“software cacheing”;而CPU实际执行时硬件层面将内存数据缓存到CPU cache中,这称为“hardware cacheing”,是对上层完全透明的。现在已经确定CC++ volatile不会再作出“将内存数据缓存到CPU寄存器”这样的优化,那上述CPU hardware caching技术就成了我们下一个怀疑的对象。
保证CPU cache一致性的方法,主要包括write-through(写直达)或者write-back(写回),write-back并不是当cache中数据更新时立即写回,而是在稍后的某个时机再写回。写直达会严重降低cpu吞吐量,所以现如今的主流处理器中通常采用写回法,而写回法又包括了write-invalidate和write-update两种方式,可先跳过。
write-back:
- write-invalidate,当某个core(如core 1)的cache被修改为最新数据后,总线观测到更新,将写事件同步到其他core(如core n),将其他core对应相同内存地址的cache entry标记为invalidate,后续core n继续读取相同内存地址数据时,发现已经invalidate,会再次请求内存中最新数据。
- write-update,当某个core(如core 1)的cache被修改为最新数据后,将写事件同步到其他core,此时其他core(如core n)立即读取最新数据(如更新为core 1中数据)。
write-back(写回法)中非常有名的cache一致性算法MESI,它是典型的强一致算法,intel就凭借MESI优雅地实现了强一致CPU,现在intel优化了下MESI,得到了MESIF,它有效减少了广播中req/rsp数量,减少了带宽占用,提高了处理器处理的吞吐量。关于MESI,这里有个可视化的MESI交互演示程序可以帮助理解其工作原理,查看MESI可视化交互程序。
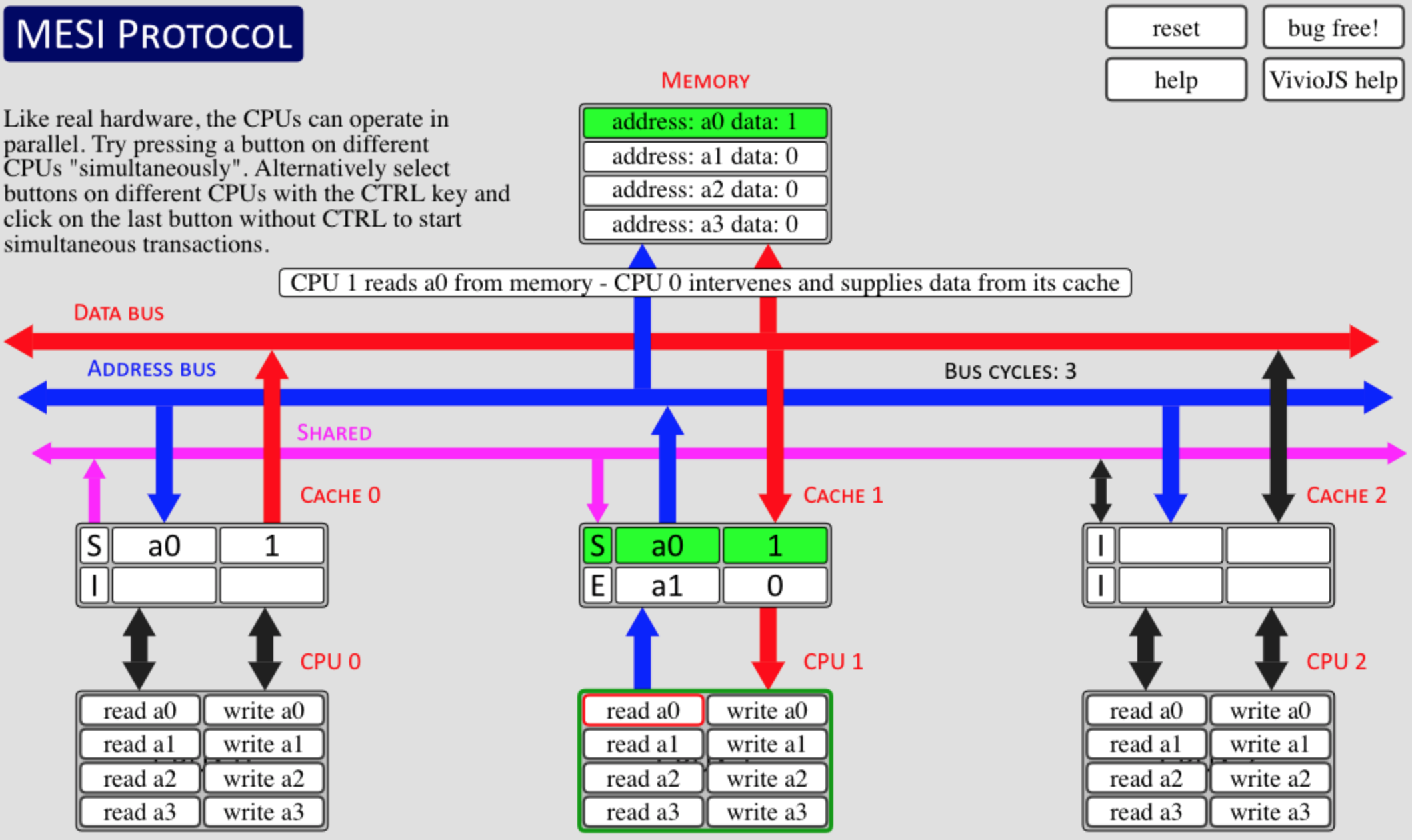
我们就先结合简单的MESI这个强一致性协议来试着理解下“x86下为什么就可以保证可见性”,结合多线程场景分析:
- 一个volatile共享变量被多个线程读取,假定这几个线程跑在不同的cpu核心上,每个核心有自己的cache,线程1跑在core1上,线程2跑在core2上。
- 现在线程1准备修改变量值,这个时候会先修改cache中的值然后稍后某个时刻写回主存或者被其他core读取。cache同步策略“write-back”,MESI就是其中的一种。处理器所有的读写操作都能被总线观测到,snoop based cache coherency,当线程2准备读取这个变量时:
- 假定之前没读取过,发现自己的cache里面没有,就通过总线向内存请求,为了保证cpu cache高吞吐量,总线上所有的事务都能被其他core观测到,core1发现core2要读取内存值,这个数据刚好在我的cache里面,但是处于dirty状态。core1可能灰采取两种动作,一种是将dirty数据直接丢给core2(至少是最新的),或者告知core2延迟read,等我先写回主存,然后core2再尝试read内存。
- 假定之前读取过了,core1对变量的修改也会被core2观测到,core1应该将其cache line标记为modified,将core2 cache line标记为invalidate使其失效,下次core2读取时从core1获取或内存获取(触发core1将dirty数据写回主存)。
这么看来只要处理器的cache一致性算法支持,并且结合volatile避免寄存器相关优化,就能轻松保证线程可见行。真的是这样吗?并不是。
认为有了MESIF volatile就可以在x86平台上实现可见性,这种理解是有问题的:
- volatile只是避免了software caching,不能避免hardware caching;
- 现在x86处理器中都引入了store buffer,volatile变量更新操作会先放入store buffer中;
- store buffer中的更新操作会尽可能快地更新到cache,有多快不确定,反正不是立即(过段时间或者有write barrier都可以清空);
- store buffer中的更新落到L1 cache后会触发MESIF操作,如将当前cache的cacheline修改为Modified,并广播给其他核MESIF invalidate请求,其他核将其放入invalidate queue中,回复ack但不立即处理;
- 等其他核下次读取时,如果还没处理完invalidate queue中的请求,就会从本地的cacheline中读取到旧值,因为此时cacheline的状态是Shared,还是可以读取的;
- 如果已经处理完了invalidate queue中的事件(过一段时间或者有read barrier都可以清空),会将对应cacheline状态修改为Invalidated,此时会重试从总线读取该cacheline对应内存块的最新数据。其他核也会observe/snoop其它核发送到总线的内存读取事件,如果它知道该内存块对应的cacheline自己的才是最新的(Modified),就会将其最新数据作为响应并写回主存,此时两边的cacheline全部改为Shared状态。
从基于对现代CPU架构、cache一致性协议的了解,我不认为x86平台下volatile就可以保证线程可见性。我甚至怀疑当时跟我提“我们用volatile之前有问题用了之后OK了”的同学是不是真的验证没问题了,还是说用的其实是atomic或者其他barriers。总之我在Intel Core i7上没有构造出合适的用例来证明volatile可以保证线程可见性,可能硬件store buffer和invalidate queue处理还是很快的,我们构造两三个线程并发读写volatile不容易复现这个问题。
而且,不同的处理器设计不一样,我们只是以MESI协议来粗略了解了x86的处理方式,对于其他弱一致性CPU,即便使用了volatile也不一定能保证线程可见性。
但若是对volatile变量读写时安插了类似MFENCE、LOCK指令也是可以保证可见性的,如何进一步判断编译器有没有生成类似barriers指令呢?还需要判断编译器(如gcc)是否有对volatile来做特殊处理,如安插MFENCE、LOCK指令之类的。上面编写的反汇编测试示例中,gcc生成的汇编没有看到lock相关的指令,但是因为我是在x86上测试的,而x86刚好是强一致CPU,我也不确定是不是因为这个原因,gcc直接图省事略掉了lock指令?所以现在要验证下,在其他非x86平台上,gcc -O2优化时做了何种处理。如果安插了类似指令,问题就解决了,我们也可以得出结论,c、c++中volatile在gcc处理下可以保证线程可见性,反之则不能得到这样的结论!
我在网站godbolt.org交叉编译测试了一下上面gcc处理的代码,换了几个不同的硬件平台也没发现有生成特定的类似MFENCE或者LOCK相关的致使处理器cache失效后重新从内存加载的指令。
备注:在某些处理器架构下,gcc确实有提供一些特殊的编译选项允许绕过CPU cache直接对内存进行读写,可参考gcc man手册“-mcache-volatile”、“-mcache-bypass”选项的描述。
想了解下CC++中volatile的真实设计“意图”,然后,在stack overflow上我又找到了这样一个回答:https://stackoverflow.com/a/12878500,重点内容已加粗显示。
[Nicol Bolas](https://stackoverflow.com/users/734069/nicol-bolas)回答中提到:
What
volatiletells the compiler is that it can’t optimize memory reads from that variable. However, CPU cores have different caches, and most memory writes do not immediately go out to main memory. They get stored in that core’s local cache, and may be written… eventually.**CPUs have ways to force cache lines out into memory and to synchronize memory access among different cores. These memory barriers allow two threads to communicate effectively. Merely reading from memory in one core that was written in another core isn’t enough; the core that wrote the memory needs to issue a barrier, and the core that’s reading it needs to have had that barrier complete before reading it to actually get the data.
volatileguarantees none of this. Volatile works with “hardware, mapped memory and stuff” because the hardware that writes that memory makes sure that the cache issue is taken care of. If CPU cores issued a memory barrier after every write, you can basically kiss any hope of performance goodbye. So C++11 has specific language saying when constructs are required to issue a barrier.
Dietmar Kühl回答中提到:
The volatile keyword has nothing to do with concurrency in C++ at all! It is used to have the compiler prevented from making use of the previous value, i.e., the compiler will generate code accessing a volatile value every time is accessed in the code. The main purpose are things like memory mapped I/O. However, use of volatile has no affect on what the CPU does when reading normal memory: If the CPU has no reason to believe that the value changed in memory, e.g., because there is no synchronization directive, it can just use the value from its cache. To communicate between threads you need some synchronization, e.g., an std::atomic
, lock a std::mutex, etc.
最后看了标准委员会对volatile的讨论:http://www.open-std.org/jtc1/sc22/wg21/docs/papers/2006/n2016.html 简而言之,就是CC++中当然也想提供java中volatile一样的线程可见性、阻止指令重排序,但是考虑到现有代码已经那么多了,突然改变volatile的语义,可能会导致现有代码的诸多问题,所以必须要再权衡一下,到底值不值得为volatile增加上述语义,当前C++标准委员会建议不改变volatile语义,而是通过新的std::atmoic等来支持上述语义。
结合自己的实际操作、他人的回答以及CC++相关标准的描述,我认为CC++ volatile确实不能保证线程可见性。但是由于历史的原因、其他语言的影响、开发者自己的误解,这些共同导致开发者赋予了CC++ volatile很多本不属于它的能力,甚至大错特错,就连Linus Torvards也在内核文档中描述volatile时说,建议尽量用memory barrier替换掉volatile,他认为几乎所有可能出现volatile的地方都可能会潜藏着一个bug,并提醒开发者一定小心谨慎。
6. 实践中如何操作
- 开发者应该尽量编写可移植的代码,像x86这种强一致CPU,虽然结合volatile也可以保证线程可见性,但是既然提供了类似memory barrier()、std::atomic等更加靠谱的用法,为什么要编写这种兼顾volatile、x86特性的代码呢?
- 开发者应该编写可维护的代码,对于这种容易引起开发者误会的代码、特性,应该尽量少用,这虽然不能说成是语言设计上的缺陷,但是确实也不能算是一个优势。
凡事都没有绝对的,用不用volatile、怎么用volatile需要开发者自己权衡,本文的目的主要是想总结CC++ volatile的“能”与“不能”以及背后的原因。由于个人认识的局限性,难免会出现错误,也请大家指正。
本文撰写于 2019-01-07, 现在拿出来分享给感兴趣的技术同行,一起学习交流。
关于对volatile的理解,会引出对内存模型的理解,即便看完一些针对内存模型的描述之后,还是会有一些开发者提出更深入细微的问题,比如lock, lock cmpxchg如何实现的,mfence、lfence、sfence如何实现的。陷入细节是可怕的,它会让我们感觉无法适可而止。
补充一篇文章,我觉得挺不错的,Memory Barrier: A Hardware View for Software Hackers。
它介绍了现在处理器的cache结构设计(包括指令cache、数据cache、cacheline、store buffer、多级cache)、cache一致性协议MESI,以及所谓的内存屏障与cache设计中cache一致性协议、store buffer、invalidate queue之间的关系。理解下这篇文章,大致搞明白硬件的工作过程,非常有助于加深这部分的理解。
本文最后更新于 2020-12-15, 补充了上述内存屏障相关的描述及参考资料。
这里还少了一层,在cpu执行更新操作时,为了避免cpu stall提高指令吞吐,写更新其实是落store buffer中的,cache中并没有立即体现出更新,cache一致性协议也还没工作……所以这个时候还需要内存屏障来讲storebuffer中的更新刷到cache,读的核上还需要通过内存屏障处理invalidate queue才能观察到新值。
那x86+volatile没有应用内存屏障,又是怎么能实现可见性的呢?
首先上述理解及质疑都是正确的思考路径,我们需要考虑的是x86体系结构里面是否有我们所不知道的东西,这篇论文也许能解答我们的问题:x86 tso model:
Moreover, different processors or hardware threads do not observably share store buffers. This is in sharp contrast to x86-CC, where each processor has a separate view order of its memory accesses and other processors' writes.
意思大概就是说x86的设计,每个处理器核心不仅有自己的内存访问视图,还有一个其他处理器的write操作的视图,这样它就能感知到谁有真正的最新的数据。所以x86上面只要c程序加了volatile避免寄存器优化就可以保证线程可见性。
参考资料
- Memory Barrier: A Hardware View for Software Hackers
- x86 TSO: A Programmer’s Model for x86 Multiprocessors
- x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors