GoNeat RPC框架设计详解
Posted 2020-02-04 00:18 +0800 by ZhangJie ‐ 12 min read
GoNeat框架一直持续演进中,抽时间整理了下框架从服务启动到结束退出这一连串流程中涉及到的设计、实现细节,希望能对想了解GoNeat框架设计、实现感兴趣的同学有帮助。 本文初衷是为了介绍GoNeat框架的设计,本人觉得按照一个服务的生命周期进行介绍,读者会比较容易接受、介绍起来也没那么枯燥,缺点是一个模块的多个实现细节可能会在不同的地方提及,读者可能需要一定的前后联想。内容比较多,也可以直接跳过部分内容阅读感兴趣的章节。 由于语言功底不是特别好,在用词、句式、断句、篇章组织上难免存在不尽如人意的地方,请多多包涵。
GoNeat RPC框架设计详解
GoNeat,追求“小而美”的设计,是基于golang开发的面向后台开发的微服务框架,旨在提升后台开发效率,让大家摆脱各种琐碎的细节,转而更加专注于服务质量本身。Simple & Powerful,是我们始终追求的设计理念。
本文从整体上介绍GoNeat的设计,GoNeat包括哪些核心部件,它们又是是如何协作的,服务运行期间涉及到哪些处理流程,等等。如果读者想更深入地了解,可以在本文基础上再阅读相关源码,或与我们开发者交流。
GoNeat 整体架构
下图展示了GoNeat的整体架构设计,包括其核心组成部分,以及不同组成部分之间的交互:
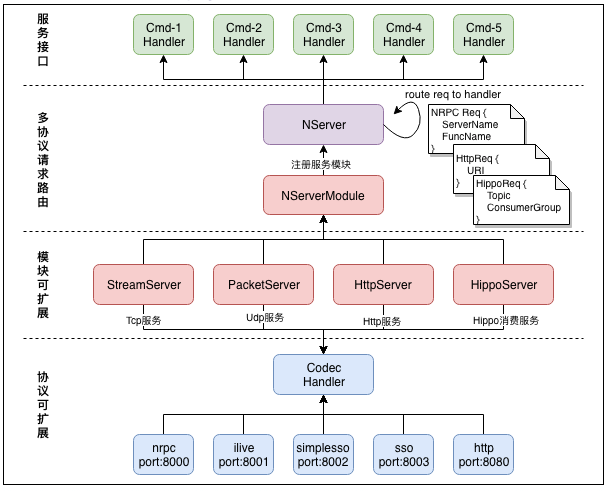
GoNeat包括如下核心组成部分:
- Server,代表一个服务实例,一个Server可以插入多个ServerModule;
- ServerModule,代表一个服务模块,实现包括StreamServer、PacketServer、HttpServer、HippoServer;
- NHandler,即Codec Handler,代表一个协议Handler,实现包括nrpc、ilive、sso、http等协议Handler;
- 不同port上可以分别提供不同协议的服务,如8000端口提供tcp/udp的nrpc服务,而8080提供http服务;
- 不同port上到达的请求,经协议Handler解析出请求,并根据请求中的命令字,找到注册的CmdHandler;
- Server将请求以函数参数的形式递交给注册的CmdHandler处理,处理完毕返回结果给调用方;
介绍完框架的核心组件之后,下面结合一个服务示例,介绍下服务启动、请求处理、服务退出的详细流程及设计细节。
GoNeat 服务示例
我们仍然使用“test_nrpc.proto”作为示例服务pb(您可以在 go-neat/demo/quickstart 中找到该示例):
file: test_nrpc.proto
syntax = "proto2";
package test_nrpc;
// BuyApple
message BuyAppleReq {
optional uint32 num = 1;
};
message BuyAppleRsp {
optional uint32 errcode = 1;
optional string errmsg = 2;
};
// SellApple
message SellAppleReq {
optional uint32 num = 1;
};
message SellAppleRsp {
optional uint32 errcode = 1;
optional string errmsg = 2;
};
// service test_nrpc
service test_nrpc {
rpc BuyApple(BuyAppleReq) returns(BuyAppleRsp); // CMD_BuyApple
rpc SellApple(SellAppleReq) returns(SellAppleRsp); // CMD_SellApple
}
使用goneat命令行工具来创建一个新的go-neat服务:
goneat create -protocol=nrpc -protofile=test_nrpc.proto -httpon
与“Program Your Next Server in GoNeat”章节不同的是,这里额外加了一个参数“-httpon”,目的是介绍支持多协议的相关处理。运行上述命令后,应生成如下目录结构的服务模板。
test_nrpc
├── Makefile
├── README.md
├── client
│ └── test_nrpc_client.go
├── conf
│ ├── log.ini
│ ├── monitor.ini
│ ├── service.ini
│ └── trace.ini
├── deploy.ini
├── log
└── src
├── exec
│ ├── exec_test_nrpc.go
│ ├── exec_test_nrpc_impl.go
│ └── exec_test_nrpc_init.go
└── test_nrpc.go
5 directories, 12 files
GoNeat 内部设计
一直没想清楚,该以什么样的方式来描述GoNeat的内部设计,想了两种叙述方式:
按照核心组件单独拎出来挨个介绍下?
这种方式比较容易介绍,但是读者不容易理解这玩意在哪些场景下用、怎么用。因为核心组件可能功能比较多,大而全地介绍反而有点虚,一次性介绍完不光读者头大,介绍的人也头大。
按照执行流程中涉及到的组件逐个介绍?
这种方式比较容易让读者明白什么场景下用到了什么组件,对组件的介绍也可以适可而止,但是同一个组件可能在多个不同的流程中被提到,需要读者适当地对思路进行下梳理。不过GoNeat框架内组件实现一般都比较简单。
综合考虑以后,决定用第二种方式进行叙述,既方便读者理解,介绍过程本身也不至于过于枯燥。
GoNeat框架是按照如下方式进行组织的,相关子工程托管在git.code.oa.com/groups/go-neat:
- core,是核心框架逻辑,负责框架整体流程处理,即某些通用能力的抽象,如监控、分布式跟踪、日志能力;
- tencent,提供了公司常用中间件,如ckv、hippo、monitor、tnm、dc、habo、l5、cmlb等等;
- common,提供了框架中一些常用的工具类实现,如共享内存操作等等;
- tool,提供了GoNeat开发所需要的一些外围工具,如代码生成工具、monitor监控打点工具等;
为大家方便使用第三方组件,也创建了components方便大家在goneat服务开发中使用:
- components,提供了第三方的一些支持,如etcd、zookeeper等等;
此外,为了方便大家理解GoNeat框架的设计,以及快速上手开发,也提供了wiki和demo:
- wiki,也就是您正在看的这份文档,所有的文档都在这里维护,如果对文档有疑问或建议,也可在此提issue;
- demo,提供了一些示例代码,助力大家快速上手goneat开发;
为方便大家在公司内网体验GoNeat,减少解决外部依赖所需要的时间(如访问github可能要申请外网访问权限等),我们也维护了go-neat/deps来维护框架的依赖(库+版本),install.sh搭建的时候会自动拉取这里的依赖。
我们建议您使用go module对依赖进行管理,goneat相关依赖已经补充在go.mod,请知悉。
GoNeat - 初始化
初始化:配置说明
GoNeat框架读取的配置文件,主要包括:
- test_nrpc/conf/service.ini,包含服务的核心配置;
- test_nrpc/conf/monitor.ini,包含服务不同接口的耗时分布的monitorid;
- test_nrpc/conf/log.ini,包含日志文件滚动方式、日志级别的相关定义;
- test_nrpc/conf/trace.ini,包含分布式跟踪相关backend的定义;
如果您已经对GoNeat配置项很熟悉,可以选择跳过该小节,当然我们还是建议通读一下以尽可能全面地了解不同的配置项,当后续您有需求要对框架做出约束或者改变的时候,有助于判断现有框架能力能否满足您的需要。
下面对各个日志文件中的配置项进行介绍:
test_nrpc/conf/service.ini,包括框架核心配置项,以及habo、业务协议、rpc相关配置项:
[service] 框架核心配置项:
日志相关:日志级别,保留日志文件数量,单日志文件的大小;
性能相关:允许的最大入tcp连接数,允许的最大并发请求数,
内存调优:workerpool允许创建最大协程数,udp收包buffer大小;
服务质量:服务接口的超时时间,处理请求时进行全局超时控制;
服务名称:分布式跟踪时用于追踪span节点;
[service] name = test_nrpc #服务名称 log.level = 1 #框架日志级别,0:DEBUG,1:INFO,2:WARN,3:ERROR log.size = 64MB #日志文件大小,默认64MB,可以指定单位B/KB/MB/GB log.num = 10 #日志文件数量,默认10个 limit.reqs = 100000 #服务允许最大qps limit.conns = 100000 #允许最大入连接数 workerpool.size = 20000 #worker数量 udp.buffer.size = 4096 #udp接收缓冲大小(B),默认1KB,请注意收发包尺寸 BuyApple.cmd.timeout = 5000 #服务接口BuyApple超时时间(ms) SellApple.cmd.timeout = 5000 #服务接口SellApple超时时间(ms)
[habo] 哈勃监控配置项:
是否启用哈勃监控;
申请的dcid,dc上报数据同步到habo;
dc上报测试环境,还是线上环境;
[habo] enabled = true #是否开启模调上报 caller = content_strike_svr #主调服务名称 dcid = dc04125 #罗盘id env = 0 #0:现网(入库tdw), 1:测试(不入库tdw)
[nrpc-service] 协议handler配置项:
nrpc协议handler监听的tcp端口;
nrpc协议handler监听的udp端口;
[nrpc-service] tcp.port = 8000 #tcp监听端口 udp.port = 8000 #udp监听端口
[http-service] 协议http配置项:
http协议监听的端口;
http请求URL前缀;
[http-service] http.port = 8080 #监听http端口 http.prefix = /cgi-bin/web #httpUrl前缀
[rpc-test_nrpc] rpc配置项:
rpc调用地址,支持ip://ip:port、l5://mid:cid、cmlb://appid(“服务发现”正在开发验证中)
传输模式,支持UDP、UDP全双工、TCP短连接、TCP长连接、TCP全双工,TCP/UDP SendOnly
rpc超时时间,包括默认的timeout以及细化到各个接口的超时时间;
rpc监控monitorid,包括总请求、成功、失败、耗时分布monitor id;
[rpc-test_nrpc] addr = ip://127.0.0.1:8000 #rpc调用地址 proto = 3 #网络传输模式, #1:UDP, #2:TCP_SHORT, #3:TCP_KEEPALIVE, #4:TCP_FULL_DUPLEX, #5:UDP_FULL_DUPLEX, #6:UDP_WITHOUT_RECV timeout = 1000 #rpc全局默认timeout BuyApple.timeout = 1000 #rpc-BuyApple超时时间(ms) SellApple.timeout = 1000 #rpc-SellApple超时时间(ms) monitor.BuyApple.timecost10 = 10001 #耗时<10ms monitor.BuyApple.timecost20 = 10002 #耗时<20ms monitor.BuyApple.timecost50 = 10003 #耗时<50ms ... monitor.BuyApple.timecost2000 = 10005 #耗时<2000ms monitor.BuyApple.timecostover2000 = 10006 #耗时>=2000ms ...
test_nrpc/conf/monitor.ini,用于监控服务接口本身的总请求量、处理成功、处理失败量,以及处理耗时分布情况:
[test_nrpc] 服务接口本身监控打点monitor id:
[test_nrpc] //服务接口-BuyApple monitor.BuyApple.timecost10=0 #接口BuyApple延时10ms monitor.BuyApple.timecost20=0 #接口BuyApple延时20ms monitor.BuyApple.timecost50=0 #接口BuyApple延时50ms ... monitor.BuyApple.timecost3000=0 #接口BuyApple延时3000ms monitor.BuyApple.timecostover3000=0 #接口BuyApple延时>3000ms // 服务接口-SellApple monitor.SellApple.timecost10=0 #接口SellApple延时10ms monitor.SellApple.timecost20=0 #接口SellApple延时20ms monitor.SellApple.timecost50=0 #接口SellApple延时50ms ... monitor.SellApple.timecost3000=0 #接口SellApple延时3000ms monitor.SellApple.timecostover3000=0 #接口SellApple延时>3000mstest_nrpc/conf/log.ini,代替service.ini中logging相关配置,用来支持工厂模式获取logger:
这里默认配置了三个logger:
- 框架处理日志log,go_neat_frame.log,最多保留5个日志文件,单文件上限100MB,写满则滚动;
- 框架请求流水log,go_neat_access.log,最多保留5个日志文件,单文件无上限,按天滚动;
- 默认log,default.log,最多保留5个日志文件,单文件上限100MB,写满则滚动;
#框架内部日志 [log-go_neat_frame] level = 1 #日志级别,0:DEBUG,1:INFO,2:WARN,3:ERROR logwrite = rolling logFileAndLine = 1 rolling.filename = go_neat_frame.log rolling.type = size rolling.filesize = 100m rolling.lognum = 5 #框架流水日志 [log-go_neat_access] level = 1 #日志级别,0:DEBUG,1:INFO,2:WARN,3:ERROR) logwrite = rolling logFileAndLine = 0 rolling.filename = go_neat_access.log rolling.type = daily rolling.lognum = 5 #服务默认日志 [log-default] level = 1 #日志级别,0:DEBUG,1:INFO,2:WARN,3:ERROR) logwrite = rolling logFileAndLine = 0 rolling.filename = default.log rolling.type = size rolling.filesize = 100m rolling.lognum = 5test_nrpc/conf/trace.ini,用于分布式跟踪相关的配置:
GoNeat框架通过opentracing api支持分布式跟踪,支持三种backend实现,zipkin、jaeger、天机阁:
[zipkin] 配置
[zipkin] enabled = true #是否启用zipkin trace service.name = test_nrpc #当前服务名称(span endpoint) service.addr = *:8000 #当前服务地址(span endpoint) collector.addr = http://9.24.146.130:8080/api/v1/spans #zipkin collector接口地址 traceId128bits = true #是否启用128bits traceId[jaeger] 配置
[jaeger] enabled = false #是否启用jaeger trace(暂未验证兼容性) service.name = test_nrpc #当前服务名称(span endpoint) service.addr = *:8000 #当前服务地址(span endpoint) collector.addr = http://9.24.146.130:8080/api/v1/spans #jaeger collector接口地址 traceId128bits = true #是否启用128bits traceId[天机阁] 配置
[tianjige] enabled = false #是否启用天机阁 trace service.name = test_nrpc #当前服务名称(span endpoint) service.addr = *:8000 #当前服务地址(span endpoint) collector.addr = 10.101.192.79:9092 #天机阁 collector接口地址 traceId128bits = true #是否启用128bits traceId appid = ${your_applied_appid} #天机阁申请的appid
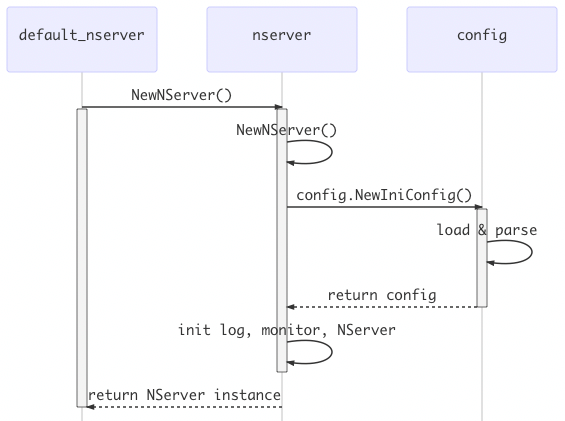
初始化:配置加载
在介绍了GoNeat依赖的配置文件及各个配置项之后,继续介绍下GoNeat的配置解析、加载过程。
GoNeat支持两种格式的配置文件:
- 一种是“ini格式”的配置文件,
- 一种是“json格式”的配置文件。
配置加载,发生在Server实例化过程中,default_nserver.NewNServer(),此时会加载service.ini、monitor.ini、log.ini,并根据配置信息完成Server实例化。
初始化:logging
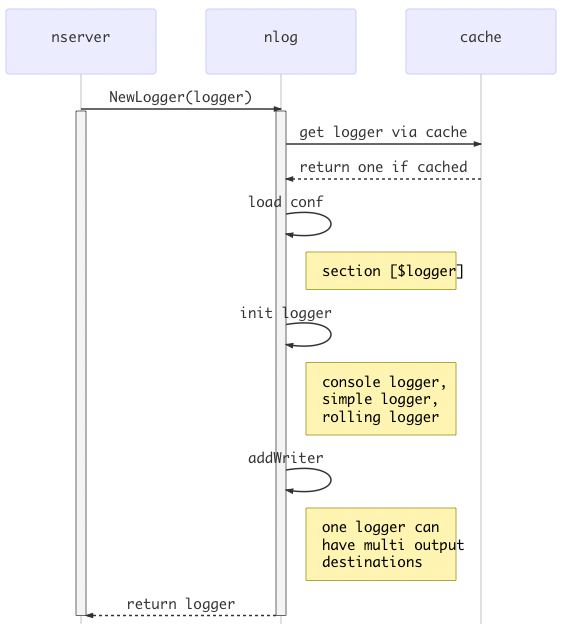
Server实例化过程中,会创建三个logger对象:
- go_neat_frame,框架处理逻辑日志,对应log.ini中的[go_neat_frame];
- go_neat_access,框架请求流水日志,对应log.ini中的[go_neat_access];
- default,框架默认日志,对应log.ini中的[default];
每个logger对象的创建都是按照如下流程去执行的,nlog.GetLogger(logger),会首先检查loggerCache中key=$logger的logger对象是否已经存在,如果存在则直接返回,反之,加载log.ini中的配置[$logger],检查logwrite配置项,logwrite指定了日志输出的目的地,如:
- console,输出到控制台;
- simple,普通日志文件,不支持滚动;
- rolling,支持滚动的日志文件,包括按照日期滚动、文件大小滚动;
logwrite允许逗号分隔多个输出,如logwrite = console, rolling,那么此时logger.Info(…)输出的信息将同时输出到控制台和滚动日志文件,详细可参考nlog.MultiWriterLogWriter实现。
nlog.MultiWriterLogWriter可以进一步重构,如支持将日志信息上报到elasticsearch、天机阁等其他远程日志系统,现在的实现稍作修改就可以支持第三方日志组件实现,elasticsearch、天机阁等远程日志组件只要实现nlog.NLog接口并完成该实现的注册即可。
初始化:tracing
分布式调用链对GoNeat框架来说是可插拔的,回想一下trace.ini,我们支持三种调用链backend实现,包括zipkin、jaeger以及公司内部的天机阁,如果希望在服务中使用tracing:
- 使用zipkin,那么在程序中
import _ “git.code.oa.com/go-neat/core/depmod/trace/zipkin即可; - 使用jaeger,那么在程序中
import _ “git.code.oa.com/go-neat/core/depmod/trace/jaeger即可; - 使用天机阁,那么在程序中
import _ “git.code.oa.com/go-neat/core/depmod/trace/tianjige即可;
当然除了import对应的调用链实现,也要对配置文件做调整:
- 使用zipkin,trace.ini里面设置zipkin.enabled = true;
- 使用jaeger,trace.ini里面设置jaeger.enabled = true;
- 使用天机阁,trace.ini里面设置tianjige.enabled = true;
如果后续想要扩展tracing backend,只需要提供对应的tracer初始化方法就可以了,类似于zipkin、jaeger、天机阁初始化方式。如果要在项目中使用该tracing实现,通过import对应实现+配置文件激活就可以。import对应的tracing backend初始化,并添加对应的初始化配置,that’s it!
初始化:协议handler
不同的业务协议,其字段定义、编解码方式可能不同,协议handler就是对业务协议的编解码进行处理。目前,GoNeat框架支持公司内大多数业务协议,如nrpc、sso、simplesso、ilive、qconn、taf等等。
协议处理方面的亮点?
GoNeat框架支持在单个进程中同时支持多种业务协议,如:
- 在port 8000提供nrpc服务;
- 在port 8001提供ilive协议;
- 在port 8080提供http服务;
同一份业务处理代码,可以通过不同的业务协议对外提供服务,在涉及到多端、多业务方交互的时候会很方便。
服务中如何支持nrpc协议?
以提供nrpc服务为例,只需要做3件事情,包括:
- 配置文件service.ini中增加[nrpc-service]配置项,指明业务协议nrpc绑定的端口,如
tcp.port = 8000; - 代码中引入对应协议handler,如
import _ "git.code.oa.com/go-neat/core/proto/nrpc/nprc_svr/default_nrpc_handler"; - 代码注册nrpc命令字及处理方法,如
default_nserver.AddExec(“BuyApple”, BuyApple);
如果要在此基础上继续支持http服务呢,一样的三件事,包括:
配置文件service.ini中增加[http-service]配置项,指明要绑定的端口及url前缀,如:
[http-service] http.port = 8080 http.prefix = /cgi-bin/web代码引入协议handler,如
import _ “git.code.oa.com/go-neat/core/proto/http/dft_httpsvr”;代码注册http uri,如
default_nserver.AddExec(“/BuyApple”, BuyApple);
That’s all!GoNeat要支持常用的业务协议,只需要做上述修改即可,是不是看上去还挺简单方便!
还记得写一个spp服务同时支持多种协议,需要在spp_handle_input里面区分端口来源,然后再调用对应的解包函数,判断请求命令字,转给对应的函数处理,每次有这种需要都需要写一堆这样的代码,好啰嗦!
框架做了什么?
读者是否注意到前文中AddExec(cmd,BuyApple),nrpc命令字BuyApple,http请求$host:8080/cgi-bin/web/BuyApple,这两种不同的请求最终是被路由到了相同的方法BuyApple进行处理,意味着开发人员无需针对不同的协议做任何其他处理,GoNeat框架帮你搞定这一切,业务代码零侵入。
真的业务代码零侵入吗?http请求参数Get、POST方式呢?nrpc协议是protbuf格式呢?同一份业务代码如何兼容?
GoNeat对不同的业务协议抽象为如下几层:
- 协议定义,如nrpc、ilive、simplesso、http包格式;
- 协议handler,完成协议的编码、解码操作(接口由NHandler定义);
- 会话session,维持客户端请求、会话信息(接口由NSession定义);
当希望扩展GoNeat的协议时,需要提供协议的包结构定义、协议的编解码实现、协议会话实现,nrpc协议对应的会话实现为NRPCSession、http协议对应的会话实现时HttpSession。
好,现在介绍下GoNeat中同一份代码func BuyApple(ctx context.Context, session nsession.NSession) (interface{}, error)如何支持多种业务协议。
file: test_nrpc/src/exec/test_nrpc.go:
func BuyApple(ctx context.Context, session nsession.NSession) (interface{}, error) {
req := &test_nrpc.BuyAppleReq{}
err := session.ParseRequestBody(req)
...
rsp := &test_nrpc.BuyAppleRsp{}
err = BuyAppleImpl(ctx, session, req, rsp)
...
return rsp, nil
}
file: test_nrpc/src/exec/test_nrpc_impl.go:
func BuyAppleImpl(ctx context.Context, session nsession.NSession, req *test_nrpc.BuyAppleReq, rsp *test_nrpc.BuyAppleRsp) error {
// business logic
return nil
}
从上面的代码中 test_nrpc.go 不难看出,秘密在于不同协议会话对NSession.ParseRequestBody(…)的实现:
- 如果是pb协议,session里面会直接通过
proto.Unmarshal(data []byte, v interface{})来实现请求解析; - 如果是http协议,session里面会多做些工作:
- 如果是
POST方法,且Content-Type=“application/json”,则读取请求体然后json.Unmarshal(...)接口;
- 如果是
- 其他情况下,读取GET/POST请求参数转成map[param]=value,编码为json再反序列化为目标结构体;
Google Protocol Buffer是一种具有自描述性的消息格式,凭借良好的编码、解码速度以及数据压缩效果,越来越多的开发团队选择使用pb来作为服务间通信的消息格式,GoNeat框架也推荐使用pb作为首选的消息格式。
由于其自描述性,pb文件被用来描述一个后台服务是再合适不过了,基于此也衍生出一些周边工具,如自动化代码生成工具goneat(由gogen重命名而来)用来快速生成服务模板、client测试程序等等。
GoNeat - 服务启动
前面零零散散地介绍了不少东西,配置文件、配置加载、logging初始化、tracing集成、协议handler注册,了解了这些之后,现在我们从整体上来认识下GoNeat服务的启动过程。
说是从整体上来认识启动流程,并不意味着这里没有新的细节要引入。中间还是会涉及到一些比较细节的问题,如tcp、udp监听如何处理的,为什么要支持端口重用,为支持平滑退出需要做哪些准备等等。这里章节划分的可能不太科学,希望按照一个GoNeat服务的生命周期来叙述,能尽可能多地覆盖到那些必要的设计和细节。
启动:实例化Server
一个GoNeat服务对应着一个Server实例,为了方便快速裸写一个GoNeat服务,go-neat/core内部提供了一个package default_nserver,代码中只需要添加如下两行代码就可以快速启动一个GoNeat服务:
package main
import (
“git.code.oa.com/go-neat/core/nserver/default_nserver”
)
func main() {
default_nserver.Serve()
}
当然,该Server实例会直接退出,因为该实例没有注册要处理的业务协议,需要注册协议handler服务才能工作。当我们创建一个pb文件,并通过命令goneat -protofile=*.proto -protocol=nrpc创建工程时,goneat自动在生成代码中包含了nrpc协议对应的协议handler,这里的协议handler做了什么呢?或者说import这个协议handler时,发生了什么呢?
import (
_ "git.code.oa.com/go-neat/core/proto/nrpc/nrpc_svr/default_nrpc_handler"
)
Server实例化过程中,会涉及到配置加载、logger实例化相关的操作,这里在GoNeat - 初始化一节中已有提及,这里相关内容不再赘述。
启动:加入协议handler
以nrpc协议handler为例:
file: go-neat/core/proto/nrpc/nrpc_svr/default_nrpc_handler/nrpc_svr_init.go
package default_nrpc_handler
import (
"git.code.oa.com/go-neat/core/nserver/default_nserver"
"git.code.oa.com/go-neat/core/proto/nrpc/nrpc_svr"
)
func init() {
default_nserver.RegisterHandler(nrpc_svr.NewNRPCHandler())
}
当import default_nrpc_handler时,func init()会自动执行,它会向上述Server实例中注册协议handler,注册过程中发生了什么呢?可参考如下简化版的代码,它主要做这些事情:
- 读取service.ini中的配置
[nrpc-service]section下的tcp.port,如果大于0创建一个StreamServer; - 读取service.ini中的配置
[nrpc-service]section下的udp.port,如果大于0创建一个PacketServer; - 将上述新创建的StreamServer和PacketServer添加到Server实例的ServerModule集合中;
file: go-neat/core/nserver/neat_svr.go
func (svr *NServer) RegisterHandler(handler NHandler) {
...
moduleNode := handler.GetProto() + "-service"
if svr.config.ReadInt32(moduleNode, "tcp.port", 0) > 0 {
nserverModule := &StreamServer{protoHandler: handler}
svr.serverModule = append(svr.serverModule, nserverModule)
}
if svr.config.ReadInt32(moduleNode, "udp.port", 0) > 0 {
nserverModule := &PacketServer{protoHandler: handler}
svr.serverModule = append(svr.serverModule, nserverModule)
}
...
}
file: test_nrpc/conf/service.ini
[nrpc-service]
tcp.port = 8000 #tcp监听端口
udp.port = 8000 #udp监听端口
启动:Server启动
default_nserver.Serve()发起了Server实例的启动,Server实例会遍历其上注册的所有ServerModule,然后逐一启动各个ServerModule,如tcp服务模块StreamServer、udp服务模块PacketServer。
file: test_nrpc/src/test_nrpc.go
package main
import (
"git.code.oa.com/go-neat/core/nserver/default_nserver"
_ "git.code.oa.com/go-neat/core/proto/nrpc/nrpc_svr/default_nrpc_handler"
_ "git.code.oa.com/go-neat/core/proto/http/dft_httpsvr"
_ "exec"
)
func main() {
default_nserver.Serve()
}
file: go-neat/core/nserver/neat_svr.go
func (svr *NServer) Serve() {
...
for _, serverModule := range svr.serverModule {
if e := serverModule.Serve(); e != nil {
...
}
}
...
}
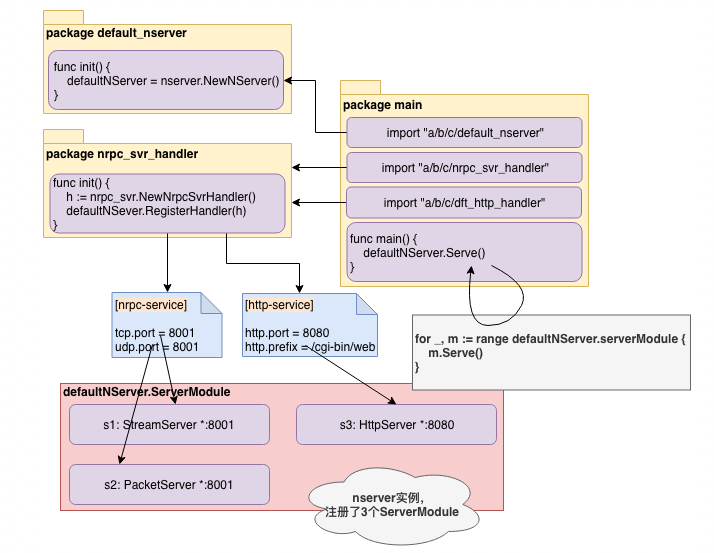
以下是Server实例启动过程图解:
- package default_nserver实例化了一个Server实例,package main只需要import这个包即可完成实例化;
- package main中import对应的协议handler,协议handler将向默认Server实例注册handler;
- 每个协议handler又有协议之分,如支持tcp、udp、http,要为不同的协议创建ServerModule并注册到Server;
- Server实例调用Serve()开始启动,该方法逐一启动已注册的所有ServerModule;
下面介绍下框架中实现的几个ServerModule,了解下它们的设计细节。
启动:ServerModule
Server允许插入多个ServerModule实现,来扩展Server的能力,如支持不同协议的ServerModule实现:tcp(StreamServer)、udp(PacketServer)、http(HttpServer)。
file: go-neat/core/nserver/neat_svr.go
type NServer struct {
serverName string
serverModule []NServerModule
...
}
file: go-neat/core/nserver/neat_comm.go
type NServerModule interface {
Init(nserver *NServer, module string, cfg *config.Ini, log *nlog.NLog) error
SetHandler(requestHandler RequestHandler)
GetProto() string
Serve() error
Close()
}
Module:StreamServer
StreamServer是GoNeat封装的面向字节流(SOCK_STREAM)的服务模块,支持tcp和unix服务。
StreamServer的创建时刻,我们在前面描述“服务启动”的部分已有提及,这里描述其启动的过程。
启动监听,处理入连接请求
func (svr *StreamServer) Serve() error {
tcpListener, err := net.Listen(svr.Network, svr.Addr)
if nil != err {
panic(fmt.Errorf("listen tcp error %s", err.Error()))
}
svr.ctx, svr.cancel = context.WithCancel(context.Background())
if nil != tcpListener {
go svr.tcpAccept(svr.protoHandler, tcpListener)
}
return nil
}
StreamServer启动的逻辑简单明了,它监听svr.Addr(传输层协议svr.Network)创建一个监听套接字,然后为该svr.ctx创建一个CancelContext,然后启动一个协程负责执行svr.tcpAccept(…),处理tcp入连接请求。
广播事件,支持平滑退出
这里提一下svr.ctx, svr.cancel,服务有自己的生命周期,有启动也有停止,服务停止的时候,存在某些未完结的任务需要清理,如HippoServer中可能拉取了一批消息但是还未处理完成,服务重启会造成消息丢失。类似这样的场景的存在,要求框架必须有能力对服务停止事件进行广播,广播给服务内的所有组件,各个组件根据需要自行执行清理动作,如HippoServer可能会选择停止继续收消息、处理完收取消息后退出。
这里的svr.ctx, svr.cancel就是负责对服务停止事件进行广播的,当Server实例停止时,会遍历其上注册的所有ServerModule并调用其Close()方法,以StreamServer为例:
// Close shutdown StreamServer
func (svr *StreamServer) Close() {
if svr.cancel != nil {
svr.cancel()
}
}
StreamServer.Close()调用了svr.cancel()来取消svr.ctx的所有child context,因为svr.ctx是整个tcp服务处理的root context,所有后续的请求处理的context都是派生自svr.ctx,当执行svr.cancel()的时候,所有派生出来的请求处理,都可以通过各个child context的Done()方法来检测StreamServer是否已经准备停止,从而采取必要的清理动作。
这里的设计,也为GoNeat服务能够优雅地“实现平滑退出”打下了基石。
建立连接,全双工处理
func (svr *StreamServer) tcpAccept(handler NHandler, listener net.Listener) {
defer listener.Close()
ctx := svr.ctx
for {
select {
case <-ctx.Done(): //服务停止,不再接受入连接请求
return
default: //建立新连接,并处理
conn, ex := listener.Accept()
if ex != nil {
log.Error("accept error:%s", ex)
} else {
if svr.connLimiter.TakeTicket() { //自我防护,对入连接数量进行限制
if tcpConn, ok := conn.(*net.TCPConn); ok {
tcpConn.SetKeepAlive(true)
tcpConn.SetKeepAlivePeriod(10 * time.Second)
}
endpoint := newEndPoint(svr, conn)
go endpoint.tcpReader() //全双工模式处理,收包、处理、回包以并发的方式进行
go endpoint.tcpWriter() //充分发挥tcp全双工的特点和优势
} else {
conn.Close() //入连接数量超过上限,关闭连接
}
}
}
}
}
对于创建好的tcp连接,StreamServer充分发挥了tcp全双工的特点和优势:
- 启动一个goroutine专门负责收包
- 启动一个goroutine专门负责回包
- 针对连接上到达的请求包,则通过协程池进行处理
- 同一个连接上的收包、处理、回包是并发的
回想下我们写C++服务端的经历,通过epoll监听每个连接套接字上的读写就绪事件,read-ready的时候要及时从连接中取出数据放到请求队列中,write-ready的时候如果请求处理完就回包。单进程多线程模型,往往有专门的io线程来进行数据包的收发,逻辑处理线程从请求队列中取走请求赶紧处理并准备好回包数据,io线程取走回包执行响应动作;如果是单进程单线程模型,io事件未就绪的情况下就要赶紧执行逻辑处理;多进程模型,则可能会采用类似spp的架构,proxy负责io,请求放入共享内存,worker进程从共享内存获取请求并写入响应,proxy再负责回包。
使用go进行开发呢?go对阻塞型系统调用进行了完整的解剖,所有的网络io、请求处理,都显得那么简单、自然,以至于都已经淡忘了C++服务端开发中存在的不同网络模型。当然,网络模型的思想在,但已经无需关注多进程单进程、多线程单线程了,只需要铭记 “tcp是全双工模式”,借助golang这一强大的基础设施来最优化tcp服务性能即可。
关于 go endpoint.tcpReader() 和 go endpoint.tcpWriter() 的细节,我们在后面服务怠速、请求处理中介绍。
过载保护,限制入连接数
StreamServer循环执行Accept()方法来建立连接,当然由于计算资源有限,服务能处理的连接数、请求数是有限的,服务需要进行一定的防护避免过载、雪崩。当svr.connLimiter.TakeTicket()成功时表示连接数未超限,可以继续处理,反之表示超出入连接数上限,关闭连接。
循环Accept()过程中,如果检测到StreamServer停止ctx.Done(),关闭监听套接字不再接受入连接请求。
过载保护,限制入请求数
除了对入tcp连接数进行限制,StreamServer也对入请求数进行限制,这部分在后续“请求处理”中介绍。
Module:PacketServer
PacketServer是GoNeat封装的面向数据报(SOCK_PACKET)的服务模块,支持udp服务。
与介绍StreamServer的方式类似,PacketServer实例化的部分前文已介绍过,这里只介绍其启动的过程。
启动监听,处理入udp请求
PacketServer.Server()中调用 reuseport.ListenPacket(...) 或者 net.ListenPacket(...) 监听svr.Addr(传输层协议类型svr.Network)创建监听套接字,并从中接收udp请求、处理请求、响应,详见svr.udpRead(…),我们会在后续“请求处理”小节中进行介绍。
// Serve start the PacketServer
func (svr *PacketServer) Serve() error {
svr.ctx, svr.cancel = context.WithCancel(context.Background())
if svr.shouldReusePort() { //如果支持重用端口,linux+darwin
reuseNum := runtime.NumCPU()
for i := 0; i < reuseNum; i++ {
udpConn, err := reuseport.ListenPacket(svr.Network, svr.Addr)
if nil != err {
panic(fmt.Errorf("listen udp error %s", err.Error()))
}
if nil != udpConn {
go svr.udpRead(svr.protoHandler, udpConn)
}
}
} else { //如果不支持端口重用,windows
udpConn, err := net.ListenPacket(svr.Network, svr.Addr)
if nil != err {
panic(fmt.Errorf("listen udp error %s", err.Error()))
}
if nil != udpConn {
go svr.udpRead(svr.protoHandler, udpConn)
}
}
return nil
}
端口重用,加速udp收包
阅读上述代码,您一定关注到了这么一点, reuseport.ListenPacket(...) 和 net.ListenPacket(...) 。在继续描述之前,需要对比下tcp收包和udp收包的区别。
- tcp是面向连接的,往往为每一个连接创建一个专门的goroutine进行收包;
- udp是无连接的,要分配多少个协程进行收包呢?1个或者N个?对同一个fd进行操作,开多个goroutine是没有价值的,那么1个的话呢,收包效率和tcp对比又有点低效。这就是PacketServer重用端口reuseport的由来了,借此提高udp收包的效率。
重用端口(REUSEPORT)和重用地址(REUSEADDR),二者诞生的初衷和作用是不同的:
- TCP/UDP连接(UDP无连接但可以connect),由五元组表示:<协议类型,源ip,源端口,目的ip,目的端口>;
- REUSEADDR解决的是监听本地任意地址0.0.0.0:port与另一个监听本地特定地址相同端口a.b.c.d:port的问题;
- REUSEPORT解决多个sockets(可能归属于相同或者不同的进程)是否允许bind到相同端口的问题,
Linux下为了避免port hijack,只允许euid相同的进程bind到相同的port(bind设置socket源port,connect设置socket目的端口),同时对于tcp listen socket、udp socket还会进行“均匀的”流量分发,也是一个轻量的负载均衡方案。
golang标准库中暂没有提供reuseport的能力,这里是引入了第三方实现,目前支持Linux+Darwin平台下的udp reuseport,Windows暂不支持。
过载保护,限制入请求数
与StreamServer类似,PacketServer也有过载保护机制,就是限制入udp请求数,我们在后续“请求处理”小节中介绍。
Module:HttpServer
HttpServer是GoNeat在golang标准库基础上封装的http服务模块,支持与StreamServer、PacketServer一样的接口注册、接口路由、接口处理逻辑。
标准库http基础上实现
从下面代码不难看出,HttpServer,该ServerModule的实现时基于标准库http package实现的,对大家来说应该都比较熟悉,但是这里也有个适配GoNeat的地方,也就是请求路由这里。
// Serve start HttpServer
func (svr *HttpServer) Serve() error {
svr.serve()
return nil
}
// serve start HttpServer
func (svr *HttpServer) serve() {
var h http.Handler = http.HandlerFunc(svr.doService)
listener, err := net.Listen("tcp", fmt.Sprintf(":%d", svr.port))
if err != nil {
panic(err)
}
server := &http.Server{
Addr: fmt.Sprintf(":%d", svr.port),
Handler: http.StripPrefix(svr.prefix, h),
}
go func() {
err := server.Serve(listener)
if err != nil {
svr.log.Error("http svr start failed, err: %v", err)
}
}()
}
httpserver请求路由转发
借助标准库实例化 http.Server{} 时,指定了将请求URI Prefix为svr.prefix的请求,交由handler h处理。而h是svr.doService(…)强制类型转换成的http.HandlerFunc。
看doService的定义,可知它确实是一个http.HandlerFunc(满足HandlerFunc的定义),这样请求就递交给了doService进行处理,doService中调用svr.requestHandler(req.Context(), httpSession)对请求进行处理,注意这里为请求专门创建了一个HttpSession,而这里的svr.requestHandler(…)是在哪里设置呢?
svr.requestHandler字段的设置,要追溯到HttpServer这个ServerModule实例化的时候,default_nserver示例会调用serverModule.SetHandler(nserver.process)方法将HttpServer.requestHandler设置为nserver.process(…),即:func process(svr *NServer, ctx Context, NSession) error才是请求处理的核心逻辑之一,涉及到鉴权、命令字路由、请求处理、tracing、耗时监控等,稍后在“请求处理”部分进行介绍。
// HttpServer defines the http NServerModule implementation
type HttpServer struct {
nserver *NServer
port int32
log *nlog.NLog
prefix string
requestHandler RequestHandler
enableGzip bool
svr *http.Server
}
...
// doService process http request `req`
func (svr *HttpServer) doService(w http.ResponseWriter, req *http.Request) {
requestLimiter := svr.nserver.reqLimiter
if requestLimiter.TakeTicket() {
addr := svr.getClientAddr(req)
defer func() {
requestLimiter.ReleaseTicket()
}()
httpSession := NewHttpSession(addr, svr.log, req, w)
ex := svr.requestHandler(req.Context(), httpSession)
if ex != nil {
w.WriteHeader(505)
return
}
if httpSession.retcode == errCodeCmdNotFound {
w.WriteHeader(404)
} else {
if len(httpSession.rspData) > 0 {
w.Write(httpSession.rspData)
}
}
} else {
svr.log.Error("http svr req overload")
}
}
过载保护,限制入http请求数
HttpServer也对入请求数进行了限制,实现对自身的过载保护,采用的方式与之前tcp、udp的处理方式类似。
Module:ScheduleServer
ScheduleServer是GoNeat为定时任务封装的一个服务模块,简化定时任务实现逻辑。
由于这里的实现逻辑比较简单、清晰,这里读者可以自己阅读代码进行了解。
Module:HippoServer
HippoServer是针对消息驱动的业务场景封装的一个消费者服务,简化消息消费的任务处理。
由于这里的实现逻辑比较简单、清晰,这里读者可以自己阅读代码进行了解。
GoNeat - 请求处理
前文描述了Server实例及各个ServerModule启动的过程,至此服务已经完全启动,可以进行请求处理了。
这里选择StreamServer、PacketServer、HttpServer作为重点描述对象,这几个ServerModule是日常业务开发中使用最频繁的,应该也是读者最希望了解的。在逐一描述之前,先介绍下用到的重要“基础设施”。
基础设施:协程池
对于操作系统而言,进程是资源分配的基本单位,线程是任务调度的基本单位。协程是相比于线程而言更加轻量的调度实体,它的轻量体现在创建、任务切换、销毁时的代价,如初始分配的栈帧大小、任务切换时保存恢复的寄存器数量等。
go官方声称可以轻松创建几百万的协程,初始协程栈大小2KB,100w的话也就是2GB,尽管当前的服务主流机器配置应该都可以支持到,但是有些问题我们却不能不去不考虑。
一个请求创建一个协程,请求量大时协程数大涨,会因为OOM Kill被操作系统杀死;
请求量上涨、协程数上涨、吃内存严重,操作系统可能会判定OOM分值时将其率先列入死亡名单,进程挂掉服务不可用,这是不可接受的。服务允许出现过载、处理超时、丢弃请求自保,但是不能挂掉。
尽管协程的创建、销毁更加轻量,但是开销还是存在;
协程池,预先创建一定数量的协程备用,协程从任务队列中获取请求进行处理,避免频繁创建、销毁的开销。同时,为了避免单一锁竞争,为每个协程分配单独的一个chan作为任务队列。
尽管协程的切换代价更小,当协程数量很多时,协程切换的代价就不能忽略了;
io事件就绪引起协程g1被唤醒,我们期望g1继续执行处理,结果协程g2的io事件就绪又唤醒协程g2,runtime scheduler可能在某个时刻(如g1进入function prologue时)将g1切换为g2……程序执行路径类似于多重中断处理,那什么时候被中断的协程g1可以继续恢复执行呢?如果协程数量很多,上下文切换的代价就需要引起关注。
特别是希望尽可能并发处理连接上的多个请求的时候,可能会比一个连接一个协程创建更多的协程。又想并发处理连接上的多个请求,又想降低协程数过多带来的上下文切换开销,通过协程池限制协程数量,也是一种选择。
其他考虑;
鉴于上述考虑,我们采用协程池来处理并发请求,而不是为每个请求创建一个协程进行处理。
基础设施:内存池
go自带内存管理,内存分配、逃逸分析、垃圾回收,内存分配算法如何提高分配效率、减少碎片是一个常被提及的问题,即便go在这方面基于tcmalloc和go自身特性做了优化,框架开发仍需要关注内存分配问题,此外还要关注gc。
考虑内存分配的情景,如果我们频繁在heap中申请内存(逃逸分析会决定分配在heap上还是stack上),不仅会增加内存分配的开销,也会增加gc扫描、回收时的压力。
内存分配次数增加引入额外开销不难理解,使用sync.Pool可以在两次gc cycle间隙返回已分配的内存来复用以减轻内存分配的次数,自然也会减轻gc扫描、标记、回收的压力。
每次 gcStart(){...} 开始新一轮gc时,会首先清理sync.Pools,清理逻辑也比较简单暴力,sync.Pools中的空闲内存块都会被清空,进入后续垃圾回收,所以内存池不适合用作连接池等有状态的对象池。
在GoNeat框架中我们将其用作收发包buffer池,用完即释放,不存在上述有状态对象被清理的问题。
Module:StreamServer
StreamServer,提供tcp网络服务,前文已经介绍了StreamServer整个生命周期的一个大致情况,包括启动监听、建立连接、接收请求、过载保护、退出等,现在我们把视角锁定在“请求处理”这个环节,进一步了解其工作过程。
再简单回顾一下,服务端StreamServer已经启动,现在正调用listener.Accept()等待客户端连接。
func (svr *StreamServer) tcpAccept(handler NHandler, listener net.Listener) {
...
for {
...
conn, ex := listener.Accept()
endpoint := newEndPoint(svr, conn)
go endpoint.tcpReader()
go endpoint.tcpWriter()
}
}
客户端发起建立连接请求,listener.Accept()将返回建立的连接,并为连接创建两个协程,一个负责收包,一个负责回包。下面我们就看下收包、解包、请求处理、组包、回包的完整过程。
收包解包
go endpoint.tcpReader() 创建了一个协程从连接上读取请求数据。由于tcp是面向字节流的无边界协议,客户端可能会同时发送多个请求包过来,这些包与包之间没有明显的数据边界,即所谓的粘包。tcp服务必须根据业务协议编解码规则处理粘包问题,否则会导致请求解码失败,更无法正常处理请求。
下面看下框架是如何进行收包解包的,网络交互过程涉及到大量的错误处理(先不展开),这里只截取了收包、解包的部分代码,方便大家理解。
func (endpoint *EndPoint) tcpReader() {
...
// 回忆下,不同的协议都有注册对应的协议handler,如nrpc协议对应NRPCHandler
handler := svr.protoHandler
// resizable buffer是网络收包过程非常倚重的一种存储结构,其大小可伸缩
// 同时为了减少内存分配、回收压力,采用了内存池的方式,预先分配特定大小的buffer用于收包,
// 如果收包数据当前buffer不够用的情况下,buffer就会动态增长以满足对存储空间的要求
buf := bufPool.Get()
defer bufPool.Put(buf)
OUT:
for {
select {
case <-ctx.Done():
return
default:
// 读取连接上到达的数据,这里设置一个读超时时间
// 如果连续一段时间(默认5min)连接上没有数据到达,则认为连接空闲,服务端为节省资源可以主动断开连接
ex := conn.SetReadDeadline(time.Now().Add(time.Millisecond * time.Duration(timeout)))
// 读取连接上的请求数据,一次读取可能遇到如下情形:
// - 完全没有读取到数据,这种会出现读取超时,for循环continue OUT,继续执行下次读取
// - 读取到了不足一个包的数据,这种会返回io.ErrUnexpectedEOF,for循环continue OUT继续收取包的剩余数据
// - 刚好读取到了一个完整包的数据,这种handler.Input(...)会返回一个请求session处理,
// - 读取到了不止一个请求包的数据,这种会返回最前面请求对应的session,剩余数据参考上述情形之一继续处理
_, ex = buf.ReadFromOnce(conn)
// 可能一次读取了多个请求包,需要循环处理
for {
buf.MarkReadIndex()
// 这里使用协议handler对buf中接收的数据进行解码操作,如果能成功解出一个请求体,则返回对应的session
nSession, ex := handler.Input(remoteAddr, buf)
// 包不完整不全直接忽略,继续收包
if io.ErrUnexpectedEOF == ex {
buf.ResetReadIndex()
continue OUT
}
// 如果包不合法,如校验发现严重错误(非收包补全)如幻数、长度校验失败,关闭连接
if ex != nil {
return
}
}
}
...
}
请求处理
假定从连接上读取的数据,经协议handler校验并解码出了一个完整的请求包,此时协议handler会创建一个匹配的session(如nrpc协议对应NRPCSession),见 nSession,ex := handler.Input(remoteAddr, buf 。创建的session用于跟踪一个请求的完整生命周期,session记录了客户端请求、服务端响应、服务处理过程中的错误事件、分布式跟踪、日志信息等等。
当StreamServer成功从连接上读取到一个请求准备开始处理之前,需要检查下当前是否已经超过了服务允许同时处理的最大请求数,如果服务端将触发过载保护动作,直接丢弃请求。
func (endpoint *EndPoint) tcpReader() {
...
OUT:
for {
select {
...
//可能一次收到多个请求包,需要循环处理
for {
buf.MarkReadIndex()
nSession, ex := handler.Input(remoteAddr, buf)
...
if requestLimiter.TakeTicket() {
svr.nserver.workpool.Submit(func() { //process
defer func() {
requestLimiter.ReleaseTicket()
}()
ex := svr.requestHandler(ctx, nSession)
if ex != nil {
svr.log.Error("[tcp-%s] handler Process error:%s", handler.GetProto(), ex.Error())
return
}
endpoint.sendChan <- nSession.GetResponseData()
cost := time.Since(nSession.ProcessStartTime()).Nanoseconds() / 1000000
svr.nserver.monitorCost(nSession.GetCmdString(), cost)
})
} else {
//过载了直接关闭连接
log.Error("[tcp-%s] [!!close conn!!] nserver reqs overload", handler.GetProto())
return
}
}
}
}
}
在请求没有触发服务过载保护的前提下,即 requestLimiter.TakeTicket() == true 时,此时会将请求递交给协程池处理,svr.nserver.workerpool.Submit(func(){…})。协程池的大致实现逻辑前面已有提及,它负责执行我们提交的任务,也就是这里workerpool.Submit(f func(){…})的参数f。注意到参数f中包含了这样一段代码:
func f() {
defer func() {
requestLimiter.ReleaseTicket()
}()
ex := svr.requestHandler(ctx, nSession)
if ex != nil {
return
}
endpoint.sendChan <- nSession.GetResponseData()
cost := time.Since(nSession.ProcessStartTime()).Nanoseconds/1000000
svr.nserver.monitorCost(nSession.GetCmdString(), cost)
}
收包处理流程结束之后,需要释放ticket,见defer函数。关于请求的正常处理流程的入口则是 svr.requestHandler(ctx, nSession) ,这里的svr.requestHandler其实就是 cmd_handler.go:process(…) 方法,在 neat_svr.go:NewNServer() 方法体中 svr.requestHandler = NewRequestHandler(),而NewRequestHandler的返回值则是cmd_handler.go:process(…) 方法。
cmd_handler.go:process(ctx context.Context, session nserver.NSession)请求处理的核心逻辑,包括请求命令字与处理方法的路由控制策略、调用用户自定义处理函数,方法执行完成后nSession中将包含该请求对应的响应结果。
组包回包
回包协程,执行下面的逻辑,循环从endpoint.sendChan中取出响应包,并发送给请求方。
func (endpoint *EndPoint) tcpWriter() {
...
for {
select {
case <-ctx.Done():
return
case dataRsp := <-endpoint.sendChan:
conn.SetWriteDeadline(time.Now().Add(time.Millisecond * time.Duration(timeout)))
dataLen, ex := conn.Write(dataRsp)
}
}
}
StreamServer的大致执行逻辑就介绍到此,更多细节信息,可以阅读下相关代码。
Module:PacketServer
PacketServer,提供udp网络服务,前文已经介绍了PacketServer整个生命周期的一个大致情况,包括启动监听、端口重用、过载保护、退出等,现在我们把视角锁定在“请求处理”这个环节,进一步了解其工作过程。
REUSEPORT
UDP是无连接协议,不存在TCP数据传输过程中的粘包问题,在收包、解包方面的处理逻辑会简单一点。与TCP不同的是,tcpClient和tcpServer建立连接的时候,tcpServer端会创建连接套接字, 我们每个连接套接字创建了一个专门的协程进行收包、解包。相比之下,UDP本身没有连接的概念,udpServer收包就是通过监听套接字,如果我们只创建一个协程来进行数据包的收包、解包操作,和tcpServer相比,在性能上就会有点逊色。
为此,udpServer的收包,这里利用了reuseport相关的能力。socket选项SO_REUSEPORT允许多线程或者多进程bind到相同的端口,网络数据包到达的时候,内核会在这些线程或进程之间进行分发,具备一定的负载均衡的能力。目前框架是基于当前CPU核数N来决定reuseport的次数,每reuseport.ListenPacket(…)一次,都会创建一个udpsocket,此时再创建一个协程用于udpsocket的收包、解包操作。这种方式和单纯从一个监听套接字上收包、解包相比,提高了收包、解包的效率。
其实TCP、UDP都可以基于reuseport进一步提升性能,框架目前将其应用在UDP上。
收包解包
相比较TCP收包而言,UDP收包的逻辑就简单了很多。
在监听套接字上循环收包,一旦检测到ctx.Done上游超时、cancel事件,则执行退出逻辑,关闭udp监听套接字。反之,则读取请求体,注意,这里有个允许同时处理请求数限制,因此会先检查 requestLimiter.TakeTicket() 是否成功,如果成功则执行实际的收包、处理逻辑,反之框架认为当前请求量过载,执行丢弃逻辑,调用方会感知到超时。
未过载的情况下,框架会从内存池里面分配或者复用一个以前分配的buffer,用来接收UDP请求体,并构建一个协议匹配的session,此时buffer已经完成了当前次的使命,将其放回内存池备用。
详细的UDP收包处理逻辑如下所示:
func (svr *PacketServer) udpRead(handler NHandler, udpConn net.PacketConn) {
defer udpConn.Close()
ctx, cancel := context.WithCancel(svr.ctx)
...
requestLimiter := svr.nserver.reqLimiter
for {
select {
case <-ctx.Done():
return
default:
if requestLimiter.TakeTicket() {
data := udpRecvBufPool.Get().([]byte)
n, remoteAddr, ex := udpConn.ReadFrom(data)
...
r := bytes.NewBuffer(data[:n])
nSession, ex := handler.Input(remoteAddr, r)
udpRecvBufPool.Put(data)
...
} else {
udpSvrReceiveExceedMax.Inc(1) //udp-svr 收包过载丢弃
}
}
}
}
请求处理
与TCP的处理方式类似,当正确收取了一个UDP请求,并为之构建好协议匹配的session之后,就会将其一个任务处理的闭包函数作为一个task递交给workerpool进行处理,svr.nserver.workpool.Submit(func() {…}),该闭包函数执行完毕后也要注意释放requestLimiter,闭包函数中的 svr.requestHandler(ctx, nSession) 就是 cmd_handler.go:process(ctx, session) 方法,与TCP的处理逻辑是一致的。之所以在svr.requestHandler和cmd_handler.go:process(…)中间再加一层抽象,是考虑到业务开发者可能希望定制化requestHandler的能力,cmd_handler.go:process(…)方法只是提供了一个还不错的默认实现。
svr.requestHandler(ctx, nSession)执行完成后,nSession中将包含请求体的响应结果,响应结果将写入sendChan中,由负责回包的协程 go svr.udpWrite(...) 执行回包操作。
func (svr *PacketServer) udpRead(handler NHandler, udpConn net.PacketConn) {
...
sendChan := make(chan *packet, 1000)
go svr.udpWrite(ctx, cancel, udpConn, sendChan)
...
for {
select {
case <-ctx.Done():
...
default:
if requestLimiter.TakeTicket() {
nSession, ex := handler.Input(remoteAddr, r)
svr.nserver.workpool.Submit(func() {
defer func() {
requestLimiter.ReleaseTicket()
}()
ex = svr.requestHandler(ctx, nSession)
dataRsp := nSession.GetResponseData()
...
sendChan <- &packet{dataRsp, remoteAddr}
})
} else {
...
}
}
}
}
组包回包
回包协程执行下面的逻辑,它循环从sendChan中收取UDP请求对应的响应,并检查响应数据是否超过64KB,超过则丢弃,反之则将响应返回给请求方。
func (svr *PacketServer) udpWrite(ctx context.Context,
cancel context.CancelFunc,
conn net.PacketConn,
sendChan chan *packet) {
defer cancel()
for {
select {
case <-ctx.Done():
return
case p := <-sendChan:
if len(p.data) > 65536 {
udpRspExceed64k.Inc(1) //udp回包超过64k
continue
}
conn.SetWriteDeadline(time.Now().Add(time.Millisecond * time.Duration(timeout)))
datalen, ex := conn.WriteTo(p.data, p.addr)
...
}
}
}
PacketServer的大致执行逻辑就介绍到此,更多细节信息,可以阅读下相关代码。
Module:HttpServer
HttpServer中有没有使用worker池(协程池)进行处理呢?该ServerModule是建立在标准库http实现之上的,GoNeat只是将请求处理的Handler传给了标准库http实现,并没有对标准库具体如何处理该请求做什么干预,比如是否采用worker池(协程池)。关于这一点,答案是否,可以查看下go标准库源码。
为每个连接创建一个协程进行处理
标准库实现中,建立监听套接字之后,调用 svr.Serve(listener) 开始接受入连接请求,该方法循环 Accept() 取出建立好的tcp连接并进行处理。标准库实现针对每一个连接都启动了一个goroutine进行处理,这与我们StreamServer的实现方式是类似的,所不同的是处理连接上并发请求的方式。
net/http/server.go:
// After Shutdown or Close, the returned error is ErrServerClosed.
func (srv *Server) Serve(l net.Listener) error {
...
for {
rw, e := l.Accept()
...
c := srv.newConn(rw)
...
go c.serve(ctx)
}
}
同一连接,串行收包、处理、回包
注意 c.Serve(ctx context.Context) 的注释部分,其中有提到HTTP/1.x pipelining的处理局限性,一个连接上可能会有多个http请求,标准库当前实现逻辑是读取一个请求、处理一个请求、发送一个响应,然后才能继续读取下一个请求并执行处理、响应,所以多个http请求的处理是串行的。
注释中也有提到,可以收取多个请求,并发处理,然后按照pipeling请求顺序按序返回结果(http协议头并没有类似我们业务协议seqno的字段),但是当前没有这么做。
连接上请求的读取、处理、回包都是在同一个连接中完成处理的,并没有像我们StreamServer、PacketServer那样将请求递交给worker池(协程池)进行处理。
net/http/server.go:
// Serve a new connection.
func (c *conn) serve(ctx context.Context) {
...
// HTTP/1.x from here on.
c.r = &connReader{conn: c}
for {
// 读取连接上的请求
w, err := c.readRequest(ctx)
// 读取一个请求,串行处理一个请求
// HTTP cannot have multiple simultaneous active requests.[*]
// Until the server replies to this request, it can't read another,
// so we might as well run the handler in this goroutine.
// [*] Not strictly true: HTTP pipelining. We could let them all process
// in parallel even if their responses need to be serialized.
// But we're not going to implement HTTP pipelining because it
// was never deployed in the wild and the answer is HTTP/2.
serverHandler{c.server}.ServeHTTP(w, w.req)
// 请求处理结束,finishRequest flush响应数据
w.cancelCtx()
w.finishRequest()
...
}
}
func (sh serverHandler) ServeHTTP(rw ResponseWriter, req *Request) {
handler := sh.srv.Handler
if handler == nil {
handler = DefaultServeMux
}
if req.RequestURI == "*" && req.Method == "OPTIONS" {
handler = globalOptionsHandler{}
}
handler.ServeHTTP(rw, req)
}
sh.svr.Handler其实就是nserver.HttpServer.doService()方法。
nserver/neat_http.go:
// doService process http request `req`
func (svr *HttpServer) doService(w http.ResponseWriter, req *http.Request) {
...
}
接管标准库Request URI路由转发
HttpServer只是在标准库http实现基础上自定义了请求Handler,所有Request URI匹配http.prefix的请求将递交给doService(…)方法处理,在doService方法内再调用nserver.process()方法转入GoNeat框架内置的命令字路由逻辑,与StreamServer、PacketServer不同的是,这里的命令字不再是rpc方法名、命令字拼接字符串,而是Request URI。
process()方法内通过URI路由到对应的处理函数Exec,并完成Exec的调用,拿到处理结果,process()方法返回处理结果,doService方法负责将响应结果写入连接中,c.Serve()中w.finishRequest()负责将响应数据flush。
至此,一次http请求、处理、响应就结束了。
而关于HTTP/2中pipelining的处理情况,与之类似,读者可以自行查阅、跟进标准库实现了解相关细节,这里不再赘述。
HttpServer的大致执行逻辑就介绍到此,更多细节信息,可以阅读下相关代码。
GoNeat - 服务怠速
前文描述了Server实例及各个ServerModule启动、请求处理的过程,当服务空闲的时候会发生什么呢?为这个阶段起了一个好听的名字”怠速”,“怠速”意味着并不是停止服务,服务依旧在空跑,那空跑阶段会发生什么呢?
GoNeat框架还是会做些事情的,比如清理、释放一些不必要的资源占用,为后续请求处理再次做好准备。
sync.Pool
前文提到,在两次gc cycle间隔期,sync.Pool可以有效提升内存分配效率,sync.Pool.Get()申请新内存或者复用已分配的内存,sync.Pool.Put(buf)重新将sync.Pool.Get()返回的buf放回池子以备复用,如果gc来临,sync.Pool中遗留的未使用的内存区将被释放掉。
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Defensively zero out everything, 2 reasons:
// 1. To prevent false retention of whole Pools.
// 2. If GC happens while a goroutine works with l.shared in Put/Get,
// it will retain whole Pool. So next cycle memory consumption would be doubled.
for i, p := range allPools {
allPools[i] = nil
for i := 0; i < int(p.localSize); i++ {
l := indexLocal(p.local, i)
l.private = nil
for j := range l.shared {
l.shared[j] = nil
}
l.shared = nil
}
p.local = nil
p.localSize = 0
}
allPools = []*Pool{}
}
虽然这部分不是框架本身所施加的,这里列出来也是为了强调下,希望开发者对计算资源保持足够的敏感度,即便是在使用自带gc机制的编程语言条件下,也应该保持这种敏感度。gc不是万能的,可以找出一种case将gc阈值推高进而将内存撑爆。
workerpool
一个workerpool的内部构造大致如下,每个worker其实就是一个goroutine,每个goroutine都绑定了一个独占的任务队列。当请求量上涨的时候,在workers都处于busy状态的情况下,workerpool会检查workers数量是否已经超过指定的上限,如果没有就继续创建worker,如此worker数量会越来越多……
workerpool
|--worker1 ---- tasks|t1|t2|t3|..|
|--worker2 ---- tasks|t4|t5|..|
|--worker3 ---- tasks||
|--worker? ---- tasks||
|--workerN ---- tasks|tx|ty|tz|
当请求量降低,甚至是空闲的时候呢?这些worker(goroutine)难道还会存在?似乎没有必要。workerpool也会定时检查workers空闲时间,每次workerpool.Submit(task)的时候,会更新实际接收该task的worker的最近使用时间lastUsedTime,如果currentTime.Since(lastUsedTime) > maxIdleDuration,则认为worker空闲,终止worker执行就可以了。
空闲连接
连接保活,是一个容易引起争论的话题,当前TCP协议本身支持连接保活,每隔一定时间发送一个TCP探针,但是也有人认为这加重了网络拥塞,保活应该在应用层自己实现,如通过心跳机制。
尽管存在这些争议,TCP保活机制仍然是首选的保活机制之一,因为它不需要引入额外的开发、保活策略。连接保活可以在客户端做,也可以在服务端做,其作用只是为了探测连接是否还健康地保持着。框架中在服务端进行保活,对于短连接的情况,继续保活显得有点多余,那为什么框架实现时选择了在服务端进行保活呢?
因为框架中对TCP完全是以双工的方式进行处理的,如在一个连接上循环收包、处理、回包,并没有做客户端是TCP短连接的假设,客户端不管是TCP短连接、长连接,StreamServer都是一样的处理逻辑,也可以理解成StreamServer鼓励客户端使用TCP长连接,所以在服务端发起保活机制也是很自然的选择。
一个进程允许打开的文件描述符(fd数量)是有限的,Linux下可以通过ulimit -s进行设置。允许打开的fd数量有限代表什么呢?在Linux下,一切皆文件,几乎所有的资源都被抽象成了文件,而每个文件”句柄“基本上都对应着一个fd。fd数量有限,意味着允许创建的socket数量也是有限的。
而ulimit -s可能给到了一个很高的值,但是如果我们不小心,也极容易泄露fd。笔者就曾经见过Web服务中client实例化没有使用单例、并且client销毁时没有close(fd)而导致fd泄露,进而迅速拖垮了现网几十台Web服务器的案例。
考虑到这种种因素,框架还是需要做些事情,将这些服务端空闲的TCP连接及时销毁,并且为了适应不同的业务场景,允许自定义连接空闲时间(记为T)。当连接上连续时间T没有请求到达,服务端认为连接空闲,并关闭连接释放系统资源。
server端关闭空闲连接,对client端来说,client收到TCP FIN包,client认为server端只是关闭了连接的写端、读端并未关闭,所以下次client继续向server发送数据时,网络io也已经设置为非阻塞,此时conn.Write(…)返回成功,但其实稍后请求到达server端,server端请求的端口早就已经没有进程使用了,因此会返回TCP RST,此时client端意识到对端已经关闭连接了,但是这个错误client如何能感知到?只能通过额外的conn.Read(…)来感知!
这里会影响到客户端TCP连接池的实现,要想实现一个可靠的TCP连接池,必须意识到这个问题的存在,我们会在后续client相关实现中继续描述。
其他问题
其他的一些不可或缺,但是可能没那么重要的点,这里先暂时不列出。
GoNeat - 监控上报
Metric
框架支持metric,将框架属性监控能力与公司组件进行了解耦,metric当前支持4个维度:counter、gauge、timer、histogram,也提供了适配monitor的metric reporter。框架上报了自身的一些关键指标,方便业务开发人员及时根据框架监控,感知业务中潜伏的问题。
Tracing
框架支持分布式跟踪,对rpc调用自动植入trace数据,业务开发无感知,只需部署或者接入相关的tracing backend(如zipkin、jaeger或者天机阁即可),可以很方便地对全链路进行跟踪、错误回溯。
Monitor
作为公司常用监控组件,go-neat/tencent/attr提供了monitor相关的封装,业务开发人员可以方便地拿来使用,并提供了批量申请monitor的工具,简轻业务开发人员监控打点的负担。
Habo
哈勃作为公司级下一代监控平台,框架层也进行了尝试,目前对模调信息进行了上报,可以很方便地对服务成功率、耗时分布进行统计,可以作为服务运营质量的一个参考指标。
GoNeat - 平滑退出
监听信号,平滑退出
框架支持监听指定信号执行平滑退出逻辑,目前来看框架退出时,会完成log刷盘、等待指定时长后再退出,等待退出期间server端可以尽力处理入队请求,但是不保证100%处理完。
context.Context超时
框架设计时对context.Context的使用场景非常明确,将其用于全局超时控制,而不用来传值。给到一个context,想了解它里面携带了什么数据,除了明确知道key没有什么更加直观的方法,而key可能分散在多个文件、同一个文件的不同地方,这非常不直观、不友好。我们不希望业务开发者来猜测,我们会在context里面塞入什么特殊的东西,我们什么都不塞,仅仅是全局超时控制。
nserver.ctx是root context,框架中ServerModule、Endpoint、收发包实现、业务逻辑处理中等等出现的context,默认都是派生自nserver.ctx,这意味着当框架收到信号执行退出逻辑时,取消nserver.ctx将取消所有的child context,我们在ServerModule、Endpoint、收发包实现、业务逻辑处理代码中等等,都植入了检测context.Done()的判断逻辑,以让系统中各个零部件及时作出步调一致的动作,如logger组件快速刷盘后退出、StreamServer关闭监听套接字尽最大努力处理已入队请求等。
还没有那么平滑?
可能看到这里,不少开发者认为,似乎还没有那么平滑,关于平滑退出的设计可以在go-neat/core issues中进行更详细地讨论。
GoNeat - More
其实还有很多地方没有介绍,如ClientAdapter实现、高并发写操作Map实现、Json Map WeakDecode、限频措施、客户端连接池更可靠地连接活性检测、可靠的应用层协议设计等,这里感兴趣的朋友可以先查阅下相关代码,稍后我们会继续补充。
写在最后,GoNeat框架一直处于比较活跃的开发状态,框架代码一直在小幅度、不间断地优化中,文档和框架比较起来,可能会略显滞后,如果您发现文档有问题,也请反馈给我们。
感谢如下同学为框架开发作出的贡献:脱敏处理 :)
GoNeat - End of Life :(
2020年7月份开始,PCG开始组织大规模的技术治理,其中就包括事实上的公司级的微服务框架tRPC的建设,自此以后我便将人力投入到了tRPC的建设、贡献中,GoNeat自这个时间点开始开始停止新特性更新。
GoNeat框架是一款在2018.3月开始陆陆续续编写的框架,到2018.8月份开始小规模测试,之后的两年里成为了团队的核心开发框架,支撑了团队几千个微服务,直到PCG建设tRPC框架后,GoNeat框架也最终走向了停止后续开发的命运。
虽然未来难免被遗忘、废弃,但是它过去也曾经”繁荣“过,几十人的活跃开发组织,几百个的issue沟通讨论、几千的commit、很多次技术分享,沉淀下来的东西也可以对新同学成长起到些指引帮助作用,对后续框架设计开发者也具有一定的参考价值,希望本文能对框架设计实现感兴趣的同学有帮助。