Locks实现:背后不为人知的故事
Posted 2021-04-17 11:32 +0800 by ZhangJie ‐ 4 min read
从事软件开发多年的你,真的理解locks背后的那些故事吗?锁是如何实现的,无锁指的又是什么,无锁真的移除了任何同步操作吗?为什么大家总是谈锁色变,锁的开销真的有那么大吗,平时编码中又该注意些什么呢?本文将结合go sync.Mutex对这些问题进行讨论。
并发:我们关心什么
并发编程,开发人员应该对原子性、指令重排有深刻的认识。
原子性
大家都了解过数据库事务的原子性,类似地,程序中也经常有些操作也需要达到类似的效果——被某种类似事务的机制“保护”起来,要么全部执行要么全部不执行。通常我们将这样需要保护的代码段称为临界区。我们希望临界区内的代码要么全部执行要么全部不执行,达到这种原子性的效果。
其实不只是代码段,给一个int变量赋值,也需要考虑原子性,因为在不同的操作系统、处理器平台上,可能一个简单的int变量赋值需要涉及多条机器指令,而在多条指令执行期间,则可能发生各种事件,比如被其他CPU核的赋值指令写乱了同一变量的数据。设想下一个int变量4字节,但是处理器平台只有16位mov指令。再或者执行i++(i为int类型)操作,实际上是包含了read-modify-write三个操作,这几个操作中间也可能插入其他指令执行。当然一条机器指令也可能不是原子的,比如add src, dst,src和dst都是内存地址,这里就涉及到读取src和dst、计算、写回dst的多个操作……更不用说一个包含了多个字段的struct结构体的赋值了。
这类原子性问题,可以通过一些相当低级的原子操作来保证,如int变量i++,可以考虑lock add指令(假定操作数位宽和int变量相同),稍复杂的数据结构(如struct)也可以使用一些“高级锁”来做同步保证,如go中的sync.Mutex。
指令重排
指令重排的根源在于CPU的设计,古老的CPU只有一条取指、译码、执行、访存、写回的功能电路。联想下假如一个单线程程序执行阻塞网络IO的时候会发生什么,整个程序全阻塞在这里干不了其他的。CPU也存在类似问题,假如一条指令执行过程中因为数据没ready的问题不能执行,或者碰到多CPU多核间cache一致性同步,那CPU会stall,后续的指令都无法执行。
所以CPU为了提高指令吞吐,增加了多条流水线设计,可以同时执行多条指令的取指、译码、执行、访存、写回,当然这其中有些指令是有数据依赖的,现代处理器支持寄存器重命名、指令乱序执行、重排序缓冲等功能,都是保证CPU执行效率的常用手段。如果想了解这方面的内容,see Computer Architecture: Dynamic Execution Core及系列课程Computer Architecture。这里贴一张超标量处理器的简图,方便大家理解这些优化手段所在的位置:
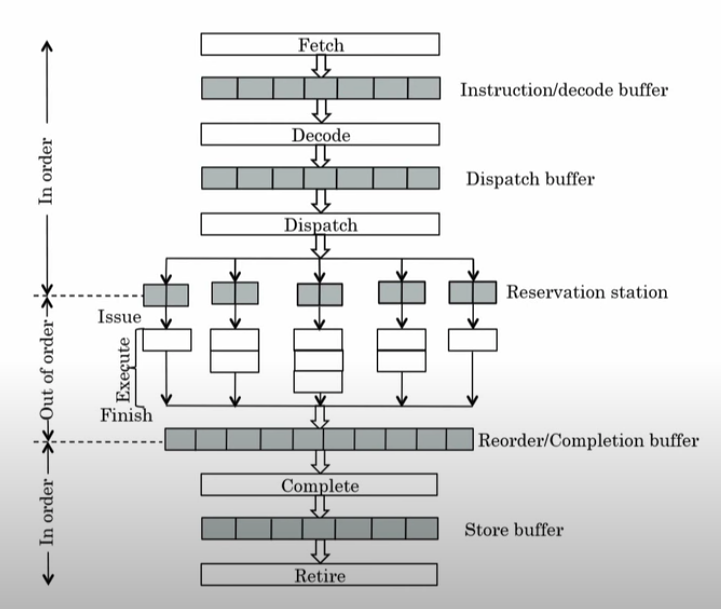
为什么要指令重排:
为什么要指令重排呢?
因为希望提高cpu指令吞吐,就要并行执行指令,要并行执行指令,就要分析出哪些指令之间有数据依赖的,表面上一个架构寄存器RAX可能被相邻多条指令使用,但是可能是一个伪数据依赖,就需要通过分析、寄存器重命名(如RAX重命名为物理寄存器R11)来消除伪数据依赖,从而允许其在执行阶段并行执行(out-of-order)。
一条指令的执行过程,会分为多个阶段,有些阶段是按序执行的(in-order),有些则是乱序执行的(out-of-order)。在指令乱序执行之后,可能会对程序正确性造成影响?影响究竟有多大,就需要参考硬件内存一致性模型,比如Intel x86处理器采用的是TSO模型(Total Store Order), see x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors。
指令重排带来的问题:
指令在CPU乱序执行,在某些并发场景下,可能会带来一些微妙的问题。比如:
type num struct {
a int
b int
}
n := &num{}
go func() { n.a = 1; n.b = 2; }() // g1
go func() { n.a = 2; n.b = 1; }() // g2
你们说最终n.a,n.b的结果是多少呢?不确定的,虽然go现在支持64位系统,现在处理器基本也都有64位mov指令,对a、b单独赋值都是原子的,但是对n整体的赋值不是。由于没有对n做保护,g1、g2中的赋值指令也没有什么数据一来,到时候乱序执行,g1 g2执行完成后,<n.a,n.b>的可能结果是:<1, 2> <1, 1> <2,1> <2,2>,这几种都有可能,而不只是有<1,2> <2,1>两种可能。
这就是指令重排造成的影响,如果我们在出现了指令重排的情况下,去做一些关键的判断逻辑,可能就会带来严重的bug。
这里重新回顾了下原子性、指令重排的含义,以及对程序正确性可能带来的影响,下面我们将尝试进一步考虑如何解决这些问题。
内存屏障:阻止指令重排
首先,我们看如何解决指令重排序问题,解铃还须系铃人,CPU流水线乱序执行带来的问题,还需要CPU自己提供解决方案。CPU如何阻止指令重排序呢?
内存屏障,可以用来阻止屏障前后的指令共同参与重排序,保证屏障后的指令不会出现在屏障前执行,保证屏障前的指令不会在屏障后执行。相当于屏障之前和之后确立了happens-before关系,保证了屏障之前的操作对屏障之后的操作都是可见的。
CPU中通常提供了如下几条指令,用以建立内存屏障:
- lock:指令前缀,修饰指令保证指令执行时的排他性、原子性和完全内存屏障
- lock cmpxchg:cmpxchg比较并交换,配合lock前缀实现CAS
- mfence:完全内存屏障(load+store)
- lfence:读内存屏障(load)
- sfence:写内存屏障(store)
一些库函数或者编程语言提供的标准库,可以选择上述某汇编指令来实现内存屏障,或者实现CAS(基本是包装下lock cmpxchg),并进一步实现各种高级锁,如spinlock、sync.Mutex。
在继续介绍内存屏障的内容之前,先说明下lock prefix的工作原理。lock prefix的使用,顾名思义,就是在一些涉及访存的指令时,编码时在指令前面添加一个前缀lock。
这个前缀有什么用呢?处理器碰到lock前缀的指令时会生成一个lock信号,这个信号会发送到总线上对要访问的操作数地址进行锁定,意思就是在当前这条指令结束之前,其操作数所在的内存区域不允许被其他指令访问。
通过这种方式保证了当前这条指令操作的原子性。
ps: 前面提到了lock指令修饰、mfence指令都可以构建完全内存屏障,都涉及到cache invalidation的操作,自然能够保证多核多线程下的可见性问题。
内存屏障:到底是什么
写并发程序,Happens-Before关系经常挂嘴边,Happens-Before关系是很容易理解的,因为它是一个编程语言的内存模型明确定义的,像Java、Go都有对内存模型的清晰定义,但是有的语言没有。举几个例子:go中包级别变量的初始化操作与包内func init()之间存在Happens-Before关系,一个锁的Unlock和下次的Lock之间也存在HB关系,chan的send、recv之间也存在HB关系……
我们想要理解的是Happens-Before定义好之后,是如何实现的?当然是借助内存屏障了。那内存屏障怎么实现的,通过处理器提供的上述几条指令。那我想再问下这几条指令干了啥,为什么这几条指令就可以实现内存屏障。
计算机中包含了太多分层的设计思想,硬件对大多数软件开发人员来说是个黑盒,似乎管好分内的事,永远将它当做一个黑盒就好了。
Well,处理器到底怎么实现内存屏障的还是比较吸引我,上面的所有回答,对我没有什么实质的帮助,那就来看看硬件层面是怎么实现的。如果不了解硬件设计、工作原理,只站在软件角度,是很难搞明白的,这个是很现实的问题,尽管了解了之后会发现很简单,但是钻到这里也确实需要时间。
内存屏障类型
- 全内存屏障(mfence):barrier之前的load/store操作均比之后的先完成,且前后的指令不能共同参与指令重排序;
- 读屏障(lfence):barrier之前的load比之后的load先完成;
- 写屏障(sfence):barrier之前的store比之后的store先完成;
不同的处理器,均提供了自己的屏障指令,但是这些指令不管有什么异同,最终都与硬件设计相关,所以来看下现代处理器的一个大致设计。
处理器架构
下面是一个用来解释内存屏障的精简的处理器架构示意图,大约包含如下几部分。
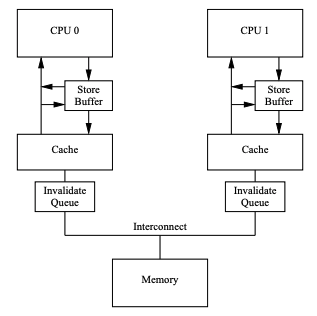
- 多个CPU或CPU Core之间通过总线连接;
- CPU通过总线与主存(memory)连接;
- 每个CPU都有自己的本地cache,通过cache一致性协议(如MESI/MESIF)与其他CPU Core维护一个一致的数据视图;
说起这里的一致性视图,我建议读者尝试了解下,会更好:
- 硬件内存一致性模型
- 编程语言内存模型
下面结合上图,我们介绍下一此数据更新操作涉及的过程。
引入store buffer
CPU对cacheline的修改,若直接落cache,一致性协议会引入不小的开销(执行cache一致性协议),CPU会stall执行的指令。为了提高指令吞吐,这里引入了store buffer。
数据更新不直接写cacheline而是先写到store buffer,后面需要时再落cache并通知其他cache失效(执行cache一致性协议),这样CPU就可以减少stall继续执行指令。
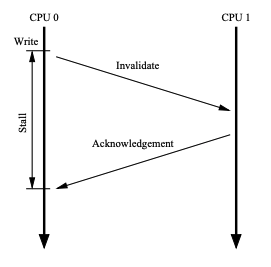
引入invalidate queue
CPU cache更新cacheline后,通知其他CPU更新cache,需通过cache一致性协议,如MESI/MESIF消息invalidate。
正常来说,收到此通知的CPU应从cache中将对应cacheline标记为无效,但是如果立即执行这个动作的话,CPU会频繁被阻断执行,所以CPU中引入了invalidate queue,收到invalidate通知后缓存起来并立即回复ACK,但延迟处理。
必要性及引入的问题
这么设计的必要性:
- 减少CPU更新本地cacheline、响应一致性协议invalidate通知导致的CPU stall问题,提高CPU整体利用率。
- 另外storebuffer、invalidate queue使我们有了指令重排的契机。
这么设计引入的问题:
- store buffer:本地cache更新不能立即被其他CPU或者CPU core观测到了,写操作对外不可见;
- invalidate queue:本地cache没有立即更新数据,上层应用看不到其他CPU更新的数据;
- cache一致性协议:它就是用来解决多个CPU共享一致性视图而设计的,但它只是一个协议,具体不同硬件设计的时候,某些屏障指令实现的时候要通过这里的cache一致性协议来保证多CPU、多核数据视图的一致性(可以参考硬件内存一致性模型、cache一致性协议相关的知识,加深理解);
处理器执行操作变化
如果没有store buffer、invalidate queue,MESI和cache如何工作?
- 当包含变量a的cacheline,其被CPU 0和CPU 1共享,当CPU 0更新该cacheline之后,会发送invalidate给CPU 1,CPU 1随即把对应的cacheline标记为invalidate;
- 当CPU 1下次读取变量a的cacheline时,发现标记为了无效,此时发出read请求,CPU 0观测到自己这边对应的cacheline是modified状态,cacheline是最新的,此时会将对应cacheline数据发送给CPU 1,这样CPU 1就观测到了最新的数据;
- CPU 0中cacheline何时写回主存?可能是被淘汰的时候,也可能是别人read的时候,这个我们先不关心。
如果引入了store buffer、invalidate queue之后,又该如何工作呢?
- 必须要有办法,将该store buffer中的更新,通知到其他CPU,这就是write barrier干的事情。它就是暂停CPU 0执行,并将CPU 0把store buffer中记录的一些更新应用到cache中,此时会触发cache一致性协议MESI通知CPU 1 cacheline invalidate;
- 必须要有办法,将CPU 1中invalidate queue记录下来的invalidate对应的cacheline及时清理掉,这就是read barrier干的事情。它就是暂停CPU 1执行,将其invalidate queue中的每个invalidate请求对应的cacheline全部标记为无效,下次读取时从内存或者CPU 0读取最新数据;
处理器屏障指令
总结一下:
- 这里的读写屏障要依赖处理器提供的屏障指令
- 在屏障指令之上,内核可以按需选择,如Linux在x86平台选择用
lock; addl来实现读写屏障 smp_mb/smp_rmb/smp_wmb,x86其实也提供了mfence、lfence、sfence。至于Linux为什么这么选择,应该是跟x86实现有关系,一条指令lock;addl同时实现全屏障/读屏障/写屏障足矣。 - 其他编程语言内存模型,通常会定义一些Happens-Before关系,这里面就隐含了各种屏障的应用。基于屏障实现的各种同步原语如mutex、semaphore等就比较常见了。
gc屏障 isn’t 内存屏障
ps:有些人还把GC Barrier和Memory Barrier搞混了,碰到不止一个同学了:
- GC Barrier,是编译器插入的一些代码片段,用来跟踪mutator对heap做的修改;
- Memory Barrier,则就是本文讨论涉及的内容,是处理器提供的一种低级的并发同步操作;
Lock prefix VS Locks
CAS,一般都是基于处理器指令 lock cmpxchg来实现的,这里一定要搞明白,这里虽然指令修饰前缀的字面含义也是lock,翻译过来也是锁,但这并非我们通俗意义上的锁。
我们平时说的轻量级锁、重量级锁,比如spinlock、futex等,或者sync.Mutex, sync.RWMutex,这些锁都是“高级锁”,而处理器指令的lock prefix只是对单条指令执行的排他性进行控制。
后者为前者实现提供了基础支持,但是不是一回事。比如,lock+cmpxchg基础上可以包装常用的cas操作,如golang中的atomic.CompareAndSwap(…),或者可以包装解决ABA问题的CAS操作。
来看一下golang中CAS操作实现:
# filename: atomic_amd64.go
//go:noescape
func Cas64(ptr *uint64, old, new uint64) bool
# filename: atomic/doc.go
func CompareAndSwapInt64(ptr *uint64, old, new uint64) bool
# filename: atomic_amd64.s
// bool ·Cas64(uint64 *val, uint64 old, uint64 new)
// Atomically:
// if(*val == *old){
// *val = new;
// return 1;
// } else {
// return 0;
// }
TEXT ·Cas64(SB), NOSPLIT, $0-25
MOVQ ptr+0(FP), BX
MOVQ old+8(FP), AX
MOVQ new+16(FP), CX
LOCK # LOCK CMPXCHGQ, 排他性比较并交换
CMPXCHGQ CX, 0(BX)
SETEQ ret+24(FP)
RET
TEXT ·CompareAndSwapInt64(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Cas64(SB) # 调用的是上面的Cas64
可以看到,它就是用lock cmpxchg来实现的,常用的atomic.CompareAndSwap也差不多了多少,还是调用的Cas64。
然后我们再来看几个atomic包下的操作,来强化下对lock指令前缀的理解,这里直接对ADDQ操作进行了lock实现了原子的加操作。
TEXT ·AddInt64(SB),NOSPLIT,$0
JMP runtime∕internal∕atomic·Xadd64(SB)
// uint64 Xadd64(uint64 volatile *val, int64 delta)
// Atomically:
// *val += delta;
// return *val;
TEXT ·Xadd64(SB), NOSPLIT, $0-24
MOVQ ptr+0(FP), BX
MOVQ delta+8(FP), AX
MOVQ AX, CX
LOCK # LOCK XADDQ,排他性的add操作
XADDQ AX, 0(BX)
ADDQ CX, AX
MOVQ AX, ret+16(FP)
RET
通常我们自己要应用cas的话,比如实现一个metrics gauge,可能会这么写:
// Gauge 时刻量
type Gauge struct {
v uint64
}
// IncrBy 时刻量+v
func (g *gauge) IncrBy(v float64) {
for {
oldBits := atomic.LoadUint64(&g.valBits)
fv := math.Float64frombits(oldBits) + v
newBits := math.Float64bits(fv)
if atomic.CompareAndSwapUint64(&g.valBits, oldBits, newBits) {
atomic.StoreUint32(&g.dirty, 1)
return
}
}
}
...
先读取原始值,计算,然后准备写回,写回的时候用了CAS,一次CAS操作不一定成功,因为可能其他协程也在尝试更新,所以我们这里要结合一个循环(自旋,spin)来保证重试成功。基于CAS的玩法一般都是这么实现的。
Locks VS Lock-free
这里读者也应该意识到了,前面CAS也是基于底层处理器的lock cmpxchg实现的,所以并不是说CAS操作就没有任何的同步措施。
有些lockfree的数据结构+算法,也是基于CAS实现的,也并不是就真的没有任何同步措施。只是没有用那些通俗意义上的“锁”(如没有用可能导致线程阻塞的互斥量、信号量)。
多线程编程时,对locks和lock-free对比,一种比较好理解的说法是:
- locks,contention managed by 3rd party (OS Kernel)
- lock-free, contention managed by the users (threads)
CAS和通俗意义的锁,相比之下,它的临界区非常小(单条指令),且不存在“锁”那样导致进程、线程、协程的挂起、恢复操作,没有上下文切换所引入的开销、调度延迟,所以开销更小一点。
能用CAS代替mutex之类锁的地方,还是用CAS,因为mutex之类的会把进程线程给挂起,即便是sync.Mutex只挂起协程,但是涉及到go runtime scheduler的介入,开销也是比单纯的CAS要大很多的。在锁竞争比较严重的情况下,sync.Mutex也会经历一个锁膨胀的过程,CAS->Spin->Semaphore->futex (spin+block threads)。
上面提了基于CAS实现一些lock-free算法,其实lock-free算法的思路有很多:
- State Machines
- CAS operations - However contention lurks here!
- @Contended Annotation - JEP 142
- Wait-Free in addition to Lock-Free Algorithms
- Thread Affinity
- x86 and busy spinning and back-off
- TSX (Transactional Synchronization Extensions)
see https://youtu.be/_uUkApe_yIk?t=2451
实现一个锁
理解了CPU lock+cmpxchg的作用以及应用之后,就可以在此基础上实现一个简单的锁。
自旋:spinlock
type SpinLock struct{
v int64
}
func (s *SpinLock) Lock() bool {
for {
if atomic.CompareAndSwap(&s.v, 0, 1) {
return true
}
}
}
func (s *SpinLock) UnLock() {
atomic.StoreInt64(&s.v, 0)
}
现在就可以拿这个锁去当做一个简单的锁去用了,但是,这种忙轮询的方式对CPU是一个比较严重的浪费,可以考虑一下如果长时间持有不了锁,是不是可以让出CPU给其他协程执行呢?可以,为了利用好CPU干有价值的事情,就应该让出去。
CAS ABA问题
在这里提一嘴吧,在使用CAS的时候,应该关注ABA问题。什么是ABA问题。假定有个volatile变量v(初始值5),现在我们并发地对其进行修改,假如出现了这样对v的一个操作序列:-1 +1,现在v的值还是5。
- 有些场景不能接受ABA问题
有些场景是不能接受ABA问题的,比如你要通过这个值的变化来判断是否有发生过什么+1 -1的操作,因为这里的值v的变化是非单调的,有增有减,这样肯定区分不了是否发生过什么,就得想其他办法。
比如你的值v用32位足够,那你可以考虑用个64位的int64,其中多出来的32位用来记录数据版本,然后用Cas64操作来代替之前的Cas32操作。
- 有些场景可以接受ABA问题
你比如前面抢到的那个自旋锁实现,SpinLock.v的值一直在0 1 0 1的变化,但是无所谓,我们仅用它来做一个当前状态的判断,而不是用它的当前值来判断以前的操作历史,如现在为0,表示没有人持有锁,但我们并不会去关心以前有没有人持有过锁。
剥夺CPU:futex?
现在我们想把不干活的任务挂起,这里的任务可能是进程、线程,也可能是协程。进程线程挂起可不是我们想要的,挂起、恢复的开销太重了。
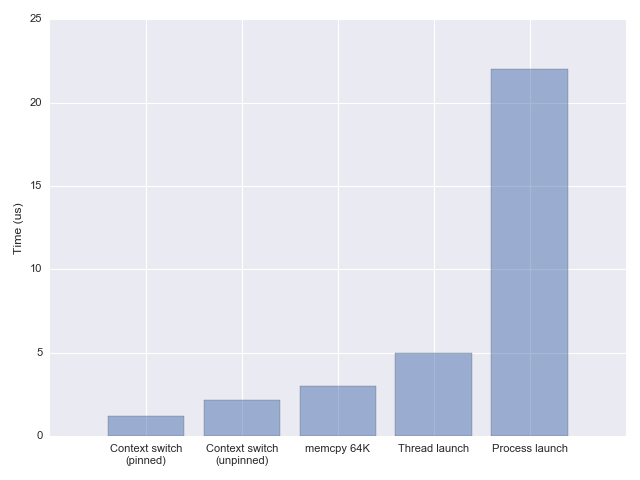
上图是一个上下文切换开销测评对比,感兴趣的话可以参考这篇文章,see measuring context switching and memory overheads for linux threads。
一般的锁实现,拿不到锁最后要么自旋,要么将当前任务给挂起,比如把进程、线程挂起,等后续锁被释放了才可以唤起等待队列中的某个进程、线程,恢复调度执行让其继续抢锁。上图中也看到了进程、线程、CPU亲和性不同场景下的上下文切换的开销,还是很明显的。
所以比较聪明的锁,都不会一下子就挂起任务。
混合锁实现
结合spin和futex的特点,实现一个混合锁:
- spinlock,自旋耗cpu,还不干活(无法推进程序执行)。自旋可以理解成为了不让出cpu让cpu一直干些杂活,比如将一个数从1加到100,加完了从头再加到100,多来几遍……纯粹是为了等锁被持有者释放。自旋锁就是自旋之后再CAS抢锁试下。但是锁竞争不严重的情况下,spinlock一般会成功,效率也高。
- futex,阻塞线程,它是Linux内核为用户代码实现同步提供的一种支持,内部维护了一个waiters队列,支持等待、唤醒、定时唤醒,为实现锁提供了方便。开发自己写代码时一般不用这玩意,而是引用在运行时或者标准库在futex基础上封装的方法。
- hybrid approach,先cas,不行再spinlock,再不行futex,分别适应没有锁竞争、少量锁竞争、严重锁竞争场景。
go语言中会怎么做呢,比如sync.Mutex?go中会做类似的处理吗?对锁的优化上大致思路差不多。只不过,go要支持轻量级协程,为了追求效率,会比常见的锁实现更细腻一点,不会在不该阻塞的时候把线程给阻塞了。
sync.Mutex
终于来到了go语言相关的设计实现,go中sync.Mutex的设计有些比较细腻的考量,本来我尝试解读下源码,发现源码mutex.Lock()/mutex.Unlock() slowpath篇幅比较长,很容易迷失在代码中抓不住主线。
所以我把解释过的源码部分删除了,我们这里只总结下一些关键的点,感兴趣的读者可以自己读源码:see https://sourcegraph.com/github.com/golang/go/-/blob/src/sync/mutex.go#L72
首先,看下sync.Mutex定义:
type Mutex struct {
state int32 // 锁状态,0:unlocked,1:locked,2:woken,4:starvation,高位
sema uint32 // 为什么是uint32? see 'man 2 futex'
}
锁膨胀过程
对照着这个结构描述下mutex.Lock()过程中可能发生的一些事情:
这里的state就是表示锁的状态,unlocked, locked, starvation等,首先会看CAS(old=unlocked,new=locked)是否成功。没有锁竞争时,这里大概率就枷锁成功了。反之,则会进入下面的lockSlow流程。
lockSlow流程中,首先也会先通过判断state是否可以通过CAS+Spin (runtime.procyield) 来加锁成功,这里不会挂起协程,更不会挂起线程。一般少量锁竞争时,这里大概率也能成功。反之,则会进入下面的sema处理流程。
sema是一道锁膨胀处理,这里的信号量(0 or 1)其效果就是一个互斥量,如果信号量acquire成功就是获得了锁,反之就是失败(semacquire函数来获得信号量)。为了避免不必要的协程挂起,一开始也是通过cansemacquire来通过cas+spin来获得信号量,成功了就等于sync.Mutex.Lock()成功,锁竞争严重些可能就会有些协程加锁失败,它们就需要继续走锁膨胀处理逻辑。此时它们将尝试加锁(更底层的一把锁runtime.mutex,
lockWithRank(semaRoot.lock)),这把锁在加锁时是遵循这样的膨胀过程:goroutine active spin (runtime.procyield) -> thread passive spin (runtime.osyield) -> linux syscall futex, 总的原则就是自旋有效的话就没必要挂起协程、线程。加锁(runtime.mutex)成功后,只是说明goroutine有资格继续抢信号量(抢到信号量就是抢到sync.Mutex)了,抢到的自然好,抢不到的怎么办呢?semaRoot上维护了一个waiters队列,抢不到的就semaRoot.queue去排队,goparkunlock会把当前协程挂起并释放掉持有的锁runtime.mutex,直到有人释放了锁并将其唤醒(sync.Mutex.UnLock->unlockSlow->semarelease->lockWithRank...semaRoot.dequeue->goready(gp))。sema这里用到的futex是一个linux系统调用(fast user-space mutex),如果你不了解futex,see https://eli.thegreenplace.net/2018/basics-of-futexes/,锁实现中常用的futex操作就是futex_wait将当前线程挂起,futex_wake将线程唤醒,涉及到线程的上下文切换,开销较大。sema虽然也是用了futex,但是其也细致考虑了不同锁竞争情况下的加锁优化,尽可能避免不必要的开销。ps: sync.Mutex.sema这个信号量一开始时为0,假设g1是第一个申请加锁的,sema==0根本对其没影响,g1通过CAS直接可以加锁成功。假设g1释放锁前g2也申请加锁,g2将走到lockSlow,假设其在前期cas+spin阶段g1未释放锁,g2只能走到sema信号量处理这里的锁膨胀逻辑,其在cansemacquire通过cas+spin抢信号量时希望sema>0,在sync.Mutex场景下,sema要么是0要么是1,现在sema==0所以g2不可能成功,只能等到sema==1的时候,那么何时sema==1?只能等到g1调用sync.Mutex.Unlock的时候,如果没有其他协程申请加锁,g1能通过CAS直接完成,但是因为g2在申请加锁,锁的state已经被写入了一些标志信息,比如waiters!=0或者starvation,g1检测到state变化后感知到有人在等待这把锁,有可能这个waiter已经goroutine parked甚至thread挂起,所以g1要通过unlockSlow去做些额外的通知工作。unlockSlow->semarelease->semaRoot.dequeue会将等待这把锁的g2给出队并通过goready(g2)去唤醒它,之后g2就可以开始继续尝试获取信号量(again,取到信号量就是取到sync.Mutex,但是前提是它得先拿到runtime.mutex)。假设此时除了g2还有g3也在等待这把锁呢,而且g3可能已经通过futex让线程挂起了,怎么搞?g1执行semarelease过程中,也会执行unlock,这个就会通过futexwakeup唤醒阻塞的线程,被暂停的g3也就可以继续执行抢锁(runtime.mutex)的动作了,抢到runtime.mutex,再去抢信号量,抢到就ok了,抢不到就在信号量上排队。
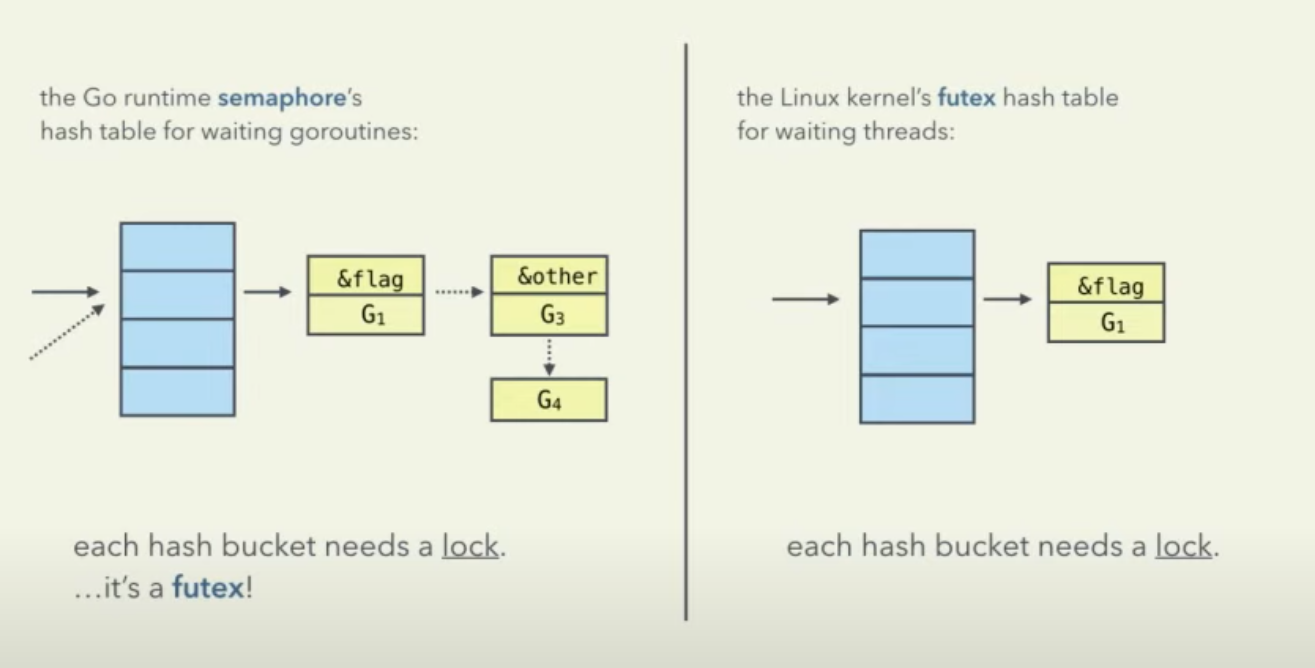
sema里面也是优先尝试走CAS、Spin路线,尽可能避免挂起协程,协程切换的开销也不能忽略。
see: https://sourcegraph.com/github.com/golang/go/-/blob/src/runtime/sema.go
type semaRoot struct{ lock mutex treap *sudog nwait uint32 } func (root *semaRoot) queue(addr *uint32, s *sudog, lifo bool) { ... } func (root *semaRoot) dequeue(addr *uint32) (found *sudog, now int64) { ... }在没有锁竞争的时候,大概率一次CAS能成功;锁竞争不严重的时候,可能自旋几次也能成功,再不行挂起协程、唤醒后再去抢锁也说不定能成功。但是锁竞争很严重的时候,你就是抢不到,那线程抢什么呢?睡觉去吧,这个时候就会用上futex让线程睡眠。
#include <linux/futex.h> #include <sys/time.h> int futex(int *uaddr, int futex_op, int val, const struct timespec *timeout, /* or: uint32_t val2 */ int *uaddr2, int val3); futex_op: - FUTEX_WAIT 保持挂起线程,除非 *uaddr != val,或者定时器超时 - FUTEX_WAKE 唤起阻塞在uaddr上的线程 - ...
这就是sync.Mutex锁膨胀的一个过程,sync.Mutex -> sema -> futex,其实每个阶段都是优先考虑cas+spin的逻辑来尽量避免挂起(协程or线程)。
注意下图中最后,uses futexes -> uses spin-locks这里,这里是说,linux futex在实现的时候也是使用了spinlock的……都是在考虑不同锁竞争情况下哪种方案更高效。
ps: linux futex根据地址做hash后找到hash bucket,bucket里面有个spinlock_t,拿到这把锁后就可以修改上面的waiters链表,比如将当前线程放入waiters后将当前线程挂起。至于这里为什么用spinlock呢?对内核锁的理解不是很全面,猜测一下,首先这里调整waiters也不怎么花时间,lock很快就释放了,线程spin一下就能等到有人释放,可能没必要用mutex休眠唤醒后再试,而且mutex阻塞上下文切换开销可能更大,所以使用spinlock。对用户态应用程序出现阻塞挂起协程让出cpu可能是件好事,但是在内核里面阻塞线程可不是件好事。linux kernel里面的锁可以参考:http://retis.sssup.it/luca/KernelProgramming/Slides/kernel_locking.pdf(p12-13)。关于futex的使用的话,看着片就够了:http://www.rkoucha.fr/tech_corner/the_futex.html#Principle_futex。

协程调度优化
另外,go sync.Mutex也做了些协程调度相关的优化,大致总结一下。sync.Mutex有两种工作模式:normal mode 和 starvation mode,两种模式对执行Lock、Unlock的goroutine会产生不同的影响。
normal mode
该模式下,waiters(goroutines)会按照申请加锁的顺序进入一个FIFO的队列,一个被唤醒的waiter不一定能够立即持有锁,它要和所有新的发起加锁请求的goroutines竞争。新到达的goroutines通常有一个优势——它们已经在CPU上运行了,并且有很多,所以一个刚被唤醒的waiter大概率会竞争锁失败。
这种情况下,这个失败的waiter会被加入到这个FIFO队列的队首,当有goroutine释放锁并尝试唤醒一个waiter时,就会优先唤醒队首的waiter,但是也只是将其标记为runnable之后丢到p.localqueue runnext里,如果放不进去会尝试放到global queue,什么时候被调度到还未可知。
而如果一个waiter竞争锁超过1ms还没有成功,就会将mutex从normal mode切换为startvation mode,下次有goroutine释放锁时,会采取更激进的方法以便让队首的waiter快速得到执行。
starvation mode
该模式下,当一个goroutine释放锁时,锁的拥有者立即从该goroutine转交给队首的waiter。新到达的goroutines不会尝试获得锁,尽管它能观察到锁好像被释放掉了。这种模式下,新到达的goroutines会追加到FIFO的队列的末尾。并且,这个拿到锁的队首的waiter,会被标记为runnable然后放入当前g.P的runnext中,并且把当前g的时间片也一并传给它使用,当前g执行goyield让出P、M之后,M将立即执行p.runnext。简言之,饥饿模式下释放锁的g直接将锁handleoff给队首的waiter,并让其更快地得到执行。
当一个waiter收到一个mutex的拥有者权限时,它会检查,如果:1)它是这个锁竞争等待队列中的最后一个waiter;或者 2)它的加锁等待时间小于1ms,此时将把mutex从starvation mode切换为normal mode。
与饥饿模式相比,正常模式下的互斥锁能够提供更好的性能,饥饿模式则能缩减goroutine 由于等待获取锁过久造成的延时。
总结
本文介绍了并发中重要的原子性、指令重排问题,以及带来的安全编码风险,然后介绍了处理器提供的一些屏障指令,以及从硬件角度介绍了屏障的工作原理,然后介绍了CAS及其使用,引出了进一步的锁、无锁、CAS的异同点,然后我们简单提了下futex重量级锁导致的进程线程挂起、恢复开销大家,最后引出了go sync.Mutex的设计实现及一系列针对协程调度延迟的优化。
希望本文对加深大家对锁的认识有帮助!
参考内容
- Memory Barriers: a Hardware View for Software Hackers,http://www.puppetmastertrading.com/images/hwViewForSwHackers.pdf
- how cpu lock cmpxchg works: http://heather.cs.ucdavis.edu/~matloff/50/PLN/lock.pdf
- don’t mix high-level locks with low-level CPU feature that happened to be renamed LOCK,https://stackoverflow.com/a/27856649/3817040
- cpu-memory, https://akkadia.org/drepper/cpumemory.pdf
- src/runtime/internal/atomic/atomic_386.s, https://sourcegraph.com/github.com/golang/go/-/blob/src/runtime/internal/atomic/atomic_386.s#L23
- sync.Mutex, https://sourcegraph.com/github.com/golang/go/-/blob/src/sync/mutex.go#L81:4
- Let’s talk locks, Kavya Joshi, https://www.youtube.com/watch?v=tjpncm3xTTc
- Atomic Operations in Hardware, https://courses.cs.washington.edu/courses/cse378/07au/lectures/L25-Atomic-Operations.pdf
- Atomic Operation, https://wiki.osdev.org/Atomic_operation
- Lock-free Algorithms for Ultimate Performance, https://www.youtube.com/watch?v=_uUkApe_yIk
- Fear and Loathing in Lock-Free Programming, https://medium.com/@tylerneely/fear-and-loathing-in-lock-free-programming-7158b1cdd50c
- measuring context switching and memory overheads for linux threads, https://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/
- basis of futexes, https://eli.thegreenplace.net/2018/basics-of-futexes/
- Computer Architecture: Dynamic Execution Core, https://youtu.be/XuCu9EEHBtk?t=1087
- x86-TSO: A Rigorous and Usable Programmer’s Model for x86 Multiprocessors, https://www.cl.cam.ac.uk/~pes20/weakmemory/cacm.pdf
- Memory Consistency Models: A Tutorial, https://www.cs.utexas.edu/~bornholt/post/memory-models.html
- Detailed approach of the futex: http://www.rkoucha.fr/tech_corner/the_futex.html#Principle_futex
- Kernel and Locking, http://retis.sssup.it/luca/KernelProgramming/Slides/kernel_locking.pdf