如何实现源代码语法高亮
Posted 2022-02-09 22:20 +0800 by ZhangJie ‐ 6 min read
语法高亮
软件开发过程中对源代码进行语法高亮是非常有必要的,通过这种方式可以将程序中不同的要素进行有效地区分,如关键字、保留字、标识符、括号匹配、注释、字符串等等。开发人员使用的IDE一般都支持语法高亮,像vim、sublime等的编辑器也可以通过插件对不同编程语言的源代码进行语法高亮支持。
如何实现
要实现语法高亮,需要做哪些工作呢?如果学习过编译原理,其实应该很容易想到,我们只需要实现一个词法分析器能够提取程序中的token序列,并通过语法分析器进行分析识别这些token具体为何物、它们之间具体是什么联系,是构成一个函数,还是构成一个表达式,还是简单到定义了一个变量、一个分支控制语句,等等。只要识别出来了,将这些不同的程序构造进行高亮显示自然不再困难。
动手实践
我们就以go语言为例,来具体讨论下如何对源码进行高亮显示。自然我们不希望重新实现一遍词法分析器、语法分析器之类的琐碎工作,我们也没有精力去重新实现一遍这类工作。尽管flex、yacc可以帮助我们简化这类工作,但是go标准库其实已经提供了package ast来帮助我们做一些语法分析相关的工作。本文我们就基于package ast来演示下如何对go源码进行语法高亮。
设计一个package colorize来提供一个colorize.Print(…)方法,来将指定的源码文件进行高亮展示,并且允许指定源文件的行号范围、io.Writer、高亮颜色风格。只用编写如下几个源文件即可:
- line_writer.go,负责按行输出,输出的时候允许指定token、高亮颜色风格,token包含了起始位置信息,所以配合颜色,即可完成对特定关键字、标识符、注释等不同程序构造的高亮显示;
- colorize.go,负责读取源文件并对其进行AST分析,将其中我们要高亮的一些程序构造提取出来,如关键字package、var、func等作为token提取出来,并构造一个colorTok(包含了token本身位置信息、属于哪一类别,这里的类别决定了最终的颜色风格);
- style.go,即高亮显示风格,不同类别对应着不同的终端颜色;
下面就是具体的源码实现了,其实这里的源码源自go-delve/delve,我在编写debugger101相关的demo时发现了go-delve/delve中存在的bug,并对其进行了修复,这里也算是简单记录分享一下吧。同学们真正有机会去尝试这个的也不多。
file: colorize.go
// Package colorize use AST analysis to analyze the source and colorize the different kinds
// of literals, like keywords, imported packages, etc.
//
// If you want to highlight source parts, for example, the identifiers.
// - firstly, colorTok must be generated by `emit(token.IDENT, n.Pos(), n.End())` in colorize.go
// - secondly, we should map the token.IDENT to some style in style.go
// - thirdly, we should define the color escape in terminal.go
package colorize
import (
"go/ast"
"go/parser"
"go/token"
"io"
"io/ioutil"
"path/filepath"
"reflect"
"sort"
)
// Print prints to out a syntax highlighted version of the text read from
// path, between lines startLine and endLine.
func Print(out io.Writer, path string, startLine, endLine, arrowLine int, colorEscapes map[Style]string) error {
buf, err := ioutil.ReadFile(path)
if err != nil {
return err
}
w := &lineWriter{w: out, lineRange: [2]int{startLine, endLine}, arrowLine: arrowLine, colorEscapes: colorEscapes}
var fset token.FileSet
f, err := parser.ParseFile(&fset, path, buf, parser.ParseComments)
if err != nil {
w.Write(NormalStyle, buf, true)
return nil
}
var base int
fset.Iterate(func(file *token.File) bool {
base = file.Base()
return false
})
type colorTok struct {
tok token.Token // the token type or ILLEGAL for keywords
start, end int // start and end positions of the token
}
toks := []colorTok{}
emit := func(tok token.Token, start, end token.Pos) {
if _, ok := tokenToStyle[tok]; !ok {
return
}
start -= token.Pos(base)
if end == token.NoPos {
// end == token.NoPos it's a keyword and we have to find where it ends by looking at the file
for end = start; end < token.Pos(len(buf)); end++ {
if buf[end] < 'a' || buf[end] > 'z' {
break
}
}
} else {
end -= token.Pos(base)
}
if start < 0 || start >= end || end > token.Pos(len(buf)) {
// invalid token?
return
}
toks = append(toks, colorTok{tok, int(start), int(end)})
}
for _, cgrp := range f.Comments {
for _, cmnt := range cgrp.List {
emit(token.COMMENT, cmnt.Pos(), cmnt.End())
}
}
ast.Inspect(f, func(n ast.Node) bool {
if n == nil {
return true
}
switch n := n.(type) {
case *ast.File:
emit(token.PACKAGE, f.Package, token.NoPos)
return true
case *ast.BasicLit:
emit(n.Kind, n.Pos(), n.End())
return true
case *ast.Ident:
// TODO(aarzilli): builtin functions? basic types?
return true
case *ast.IfStmt:
emit(token.IF, n.If, token.NoPos)
if n.Else != nil {
for elsepos := int(n.Body.End()) - base; elsepos < len(buf)-4; elsepos++ {
if string(buf[elsepos:][:4]) == "else" {
emit(token.ELSE, token.Pos(elsepos+base), token.Pos(elsepos+base+4))
break
}
}
}
return true
}
nval := reflect.ValueOf(n)
if nval.Kind() != reflect.Ptr {
return true
}
nval = nval.Elem()
if nval.Kind() != reflect.Struct {
return true
}
tokposval := nval.FieldByName("TokPos")
tokval := nval.FieldByName("Tok")
if tokposval != (reflect.Value{}) && tokval != (reflect.Value{}) {
emit(tokval.Interface().(token.Token), tokposval.Interface().(token.Pos), token.NoPos)
}
for _, kwname := range []string{"Case", "Begin", "Defer", "Package", "For", "Func", "Go", "Interface", "Map", "Return", "Select", "Struct", "Switch"} {
kwposval := nval.FieldByName(kwname)
if kwposval != (reflect.Value{}) {
kwpos, ok := kwposval.Interface().(token.Pos)
if ok && kwpos != token.NoPos {
emit(token.ILLEGAL, kwpos, token.NoPos)
}
}
}
return true
})
sort.Slice(toks, func(i, j int) bool { return toks[i].start < toks[j].start })
flush := func(start, end int, style Style) {
if start < end {
w.Write(style, buf[start:end], end == len(buf))
}
}
cur := 0
for _, tok := range toks {
flush(cur, tok.start, NormalStyle)
flush(tok.start, tok.end, tokenToStyle[tok.tok])
cur = tok.end
}
if cur != len(buf) {
flush(cur, len(buf), NormalStyle)
}
return nil
}
file: style.go
package colorize
import "go/token"
// Style describes the style of a chunk of text.
type Style uint8
const (
NormalStyle Style = iota
KeywordStyle
StringStyle
NumberStyle
CommentStyle
LineNoStyle
ArrowStyle
)
var tokenToStyle = map[token.Token]Style{
token.ILLEGAL: KeywordStyle,
token.COMMENT: CommentStyle,
token.INT: NumberStyle,
token.FLOAT: NumberStyle,
token.IMAG: NumberStyle,
token.CHAR: StringStyle,
token.STRING: StringStyle,
token.BREAK: KeywordStyle,
token.CASE: KeywordStyle,
token.CHAN: KeywordStyle,
token.CONST: KeywordStyle,
token.CONTINUE: KeywordStyle,
token.DEFAULT: KeywordStyle,
token.DEFER: KeywordStyle,
token.ELSE: KeywordStyle,
token.FALLTHROUGH: KeywordStyle,
token.FOR: KeywordStyle,
token.FUNC: KeywordStyle,
token.GO: KeywordStyle,
token.GOTO: KeywordStyle,
token.IF: KeywordStyle,
token.IMPORT: KeywordStyle,
token.INTERFACE: KeywordStyle,
token.MAP: KeywordStyle,
token.PACKAGE: KeywordStyle,
token.RANGE: KeywordStyle,
token.RETURN: KeywordStyle,
token.SELECT: KeywordStyle,
token.STRUCT: KeywordStyle,
token.SWITCH: KeywordStyle,
token.TYPE: KeywordStyle,
token.VAR: KeywordStyle,
}
file: line_writer.go
package colorize
import (
"fmt"
"io"
)
type lineWriter struct {
w io.Writer
lineRange [2]int
arrowLine int
curStyle Style
started bool
lineno int
colorEscapes map[Style]string
}
func (w *lineWriter) style(style Style) {
if w.colorEscapes == nil {
return
}
esc := w.colorEscapes[style]
if esc == "" {
esc = w.colorEscapes[NormalStyle]
}
fmt.Fprintf(w.w, "%s", esc)
}
func (w *lineWriter) inrange() bool {
lno := w.lineno
if !w.started {
lno = w.lineno + 1
}
return lno >= w.lineRange[0] && lno < w.lineRange[1]
}
func (w *lineWriter) nl() {
w.lineno++
if !w.inrange() || !w.started {
return
}
w.style(ArrowStyle)
if w.lineno == w.arrowLine {
fmt.Fprintf(w.w, "=>")
} else {
fmt.Fprintf(w.w, " ")
}
w.style(LineNoStyle)
fmt.Fprintf(w.w, "%4d:\t", w.lineno)
w.style(w.curStyle)
}
func (w *lineWriter) writeInternal(style Style, data []byte) {
if !w.inrange() {
return
}
if !w.started {
w.started = true
w.curStyle = style
w.nl()
} else if w.curStyle != style {
w.curStyle = style
w.style(w.curStyle)
}
w.w.Write(data)
}
func (w *lineWriter) Write(style Style, data []byte, last bool) {
cur := 0
for i := range data {
if data[i] == '\n' {
if last && i == len(data)-1 {
w.writeInternal(style, data[cur:i])
if w.curStyle != NormalStyle {
w.style(NormalStyle)
}
if w.inrange() {
w.w.Write([]byte{'\n'})
}
last = false
} else {
w.writeInternal(style, data[cur:i+1])
w.nl()
}
cur = i + 1
}
}
if cur < len(data) {
w.writeInternal(style, data[cur:])
}
if last {
if w.curStyle != NormalStyle {
w.style(NormalStyle)
}
if w.inrange() {
w.w.Write([]byte{'\n'})
}
}
}
运行测试
下面是测试文件,我们定义了一个表示源码内容的字符串,并通过gomonkey mock掉了ioutil.ReadFile(…)的操作让其返回定义的源码字符串,然后执行colorize.Print(…)对其进行高亮显示。
file: colorize_test.go
package colorize_test
import (
"bytes"
"fmt"
"io/ioutil"
"reflect"
"testing"
"github.com/agiledragon/gomonkey/v2"
"github.com/hitzhangjie/dlv/pkg/terminal/colorize"
)
var src = `package main
// Vehicle defines the vehicle behavior
type Vehicle interface{
// Run vehicle can run in a speed
Run()
}
// BMWS1000RR defines the motocycle bmw s1000rr
type BMWS1000RR struct {
}
// Run bwm s1000rr run
func (a *BMWS1000RR) Run() {
println("I can run at 300km/h")
}
func main() {
var vehicle = &BMWS1000RR{}
vehicle.Run()
}
`
const terminalHighlightEscapeCode string = "\033[%2dm"
const (
ansiBlack = 30
ansiRed = 31
ansiGreen = 32
ansiYellow = 33
ansiBlue = 34
ansiMagenta = 35
ansiCyan = 36
ansiWhite = 37
ansiBrBlack = 90
ansiBrRed = 91
ansiBrGreen = 92
ansiBrYellow = 93
ansiBrBlue = 94
ansiBrMagenta = 95
ansiBrCyan = 96
ansiBrWhite = 97
)
func colorizeCode(code int) string {
return fmt.Sprintf(terminalHighlightEscapeCode, code)
}
var colors = map[colorize.Style]string{
colorize.KeywordStyle: colorizeCode(ansiYellow),
colorize.ArrowStyle: colorizeCode(ansiBlue),
colorize.CommentStyle: colorizeCode(ansiGreen),
colorize.LineNoStyle: colorizeCode(ansiBrWhite),
colorize.NormalStyle: colorizeCode(ansiBrWhite),
colorize.NumberStyle: colorizeCode(ansiBrCyan),
colorize.StringStyle: colorizeCode(ansiBrBlue),
}
func TestPrint(t *testing.T) {
p := gomonkey.ApplyFunc(ioutil.ReadFile, func(name string) ([]byte, error) {
return []byte(src), nil
})
defer p.Reset()
buf := &bytes.Buffer{}
colorize.Print(buf, "main.go", bytes.NewBufferString(src), 1, 30, 10, colors)
colorize.Print(os.Stdout, "main.go", bytes.NewBufferString(src), 1, 30, 10, colors)
}
现在运行这个测试用例go test -run TestPrint,程序运行结果如下:
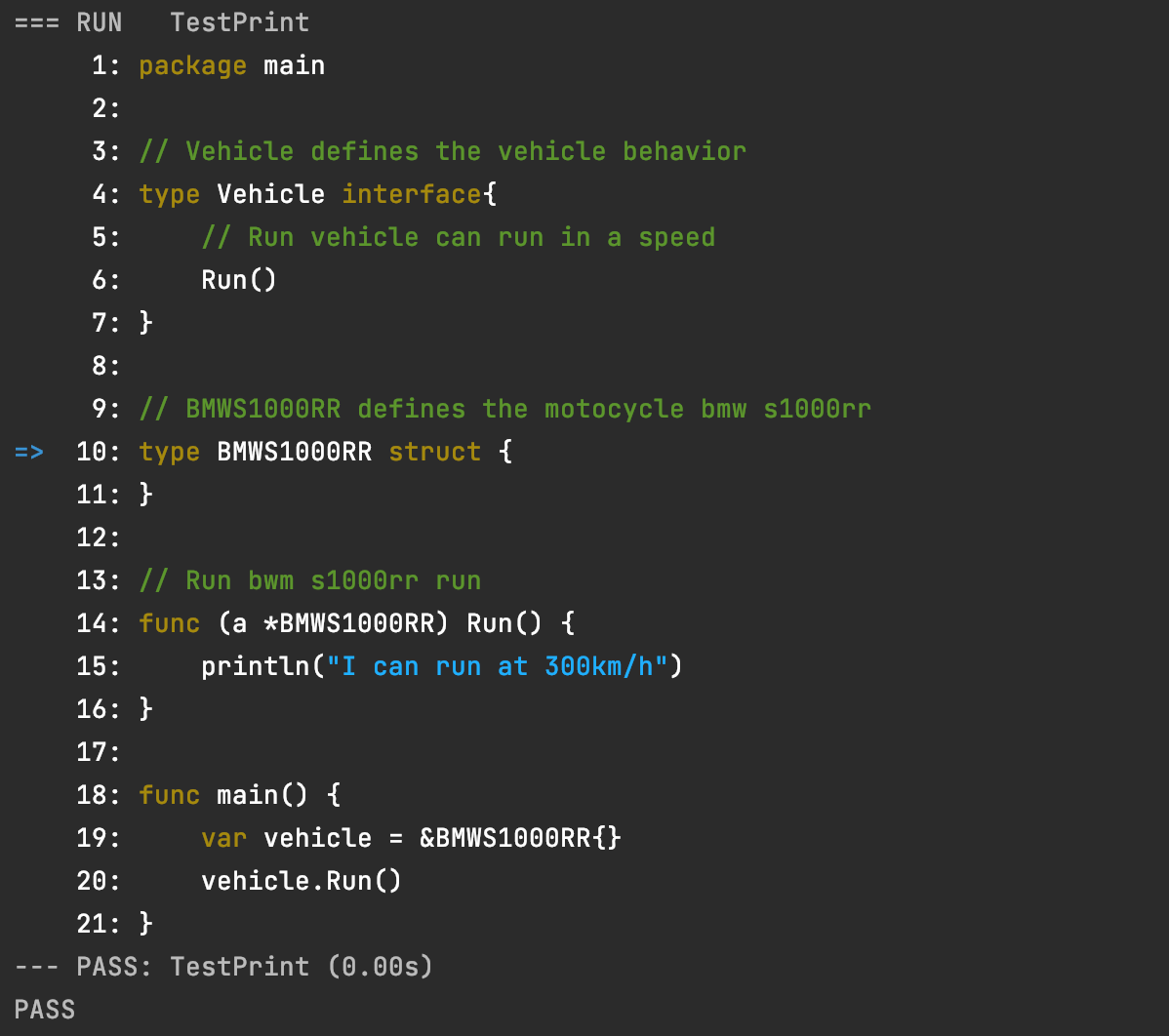
我们看到程序中的部分程序元素被高亮显示了,当然我们只识别了简单的一小部分,关键字、字符串、注释,实际IDE中会分析的更加的细致,大家在使用IDE的时候应该也都有这方面的体会。
本文小结
本文简单总结了如何基于go ast对源代码进行语法分析并进行高亮显示,希望读者能了解到这里的知识点,并能认识到编译原理的相关知识真的是可以用来做些有价值、有意思的东西的。再比如,我们实现一些linters对源码进行检查(如golangci-linter),作者之前还写过一篇文章是讲述如何对go程序进行可视化,有些IDE还支持自动生成classgram、callgraph等等,这些也是对go ast的另一种应用。
新的一年与大家共勉,做有追求的工程师,知其然知其所以然 :)