一致性hash负载均衡方案的思考
Posted 2022-08-06 17:16 +0800 by ZhangJie ‐ 4 min read
常见的负载均衡策略
客户端完成被调服务的服务发现后,获得了一批实例节点列表,现在要借助合适的负载均衡算法来选择一个实例完成请求处理。
常见的负载均衡算法包括:
- 轮询:每一次网络请求按照顺序发放给下节点列表中的下一个节点,这种情况适用于节点配置相同并且平均服务请求相对均衡的情况
- 加权轮询:考虑了不同节点的硬件配置情况,如节点a、b、c性能有低到高,权重设置为1、3、6,则按照权重分配10%、30%、60%的请求给到节点,这种可以避免高性能机器负载低、避免性能差机器过载
- 随机:随机选择一个节点来处理请求,这种在请求量比较大的情况下能达到相对均衡的分布,同样适用于机器配置相同的情况
- 加权随机:考虑了不同节点的硬件配置情况,类似加权轮询,只不过选择下一个节点时是基于随机选择,而非轮询的方式
- 余数hash:根据某个key对节点数做取模运算,比如节点数为n,根据请求中的m = uid % n,表示用节点列表中第m个节点来作为服务节点。当key分布范围比较广能达到相对均衡,选择key字段的时候要考虑下key分布情况。使用hash的场景,一般是因为后端节点有状态可复用(或者希望借此减少并发冲突),但真实环境中,节点故障是常态,尤其是在容器化部署场景下自动化扩缩容,hash会导致集群中所有节点状态无法被复用。一般会用一致性hash代替hash。
- 一致性hash:一致性hash是对hash的优化,一致性这里强调的就是节点加入、离开后尽量保证大多数请求仍然能路由到该路由的节点,而不是新加入的节点,同时为了避免新加入、离开节点导致的负载不均衡问题,引入了虚拟节点的概念,每个物理节点都对应着hash环上一定数量的虚拟节点,这些节点混在一起,能实现各个节点负载的相对均衡。节点数量该选择多少呢?一个比较直观的认识是可能虚拟节点越多越均衡,但是数量过多也会有开销,这与虚拟节点的hash计算、存储有关系,本文后面讨论。
- 按响应速度:有些负载均衡设备,会根据与后端服务节点间的ping延时来选择一个响应时间最短的。类似的也可以根据client、server之间的ping延时或者请求处理响应时间来选择。
- 按最少连接数:对于某些请求处理时间比较长的场景,如ftp传输等,一个tcp连接存在的时间可能比较长,连接数比较多的可能代表该节点负载比较重,因此会开率选择连接数比较少的来提供服务。
- 其他
负载均衡算法有很多,之所以这么多也是因为应用场景的差异,根据合适的场景选择适用的负载均衡算法。
调研一致性hash策略及其可替代方案
对一致性hash方案及其可替代方案进行调研、对比。
余数hash
余数hash,简单讲就是那个key去算出hash值,然后对节点数量取模,m = hash(key) % n,用节点列表中的第m个节点去做请求处理。 如果节点数变化非常不频繁,或者说key remapping(rebalancing)过程中带来的开销不大、影响不大,那用余数hash也无所谓。
但是现实场景中,比如一些有状态服务,如果remapp后映射到了与先前不同的节点,或者容器化部署时节点数经常变更,不满足适用余数hash的条件。
比较常见的对策,就是采用一致性hash。
一致性hash
简要介绍
一致性hash能够缓解节点加入、离开时rebalancing导致的一些hash节点改变的问题,在以下场景中就更有优势:
服务是有状态的,这样大多数路由仍然能路由到原来的节点,状态可以复用;
即使服务不是有状态的,将原来路由到节点n的请求及其后续请求继续路由到该节点,也可能存在更好的局部性处理(locality),
举个例子(可能不很恰当哈): 比如有个个人展示页要展示头像昵称、最近游戏记录,假设之前有个什么客户端请求uid=xxx的请求路由到了节点n拉取过了昵称头像并cache,后面该展示页也路由到该节点的话就可以复用该cache。
假设key空间中值数量为k,节点数为n,那么当发生remapping时,笼统估算有k/n不命中原来的节点。
关于实现
关于一致性hash的实现:
- 构建一个一致性hash环,一个数组就可以实现
- 选定节点的key,如ip,hash(key),然后再hash环上对应位置存储该节点信息,考虑到hash环大小需要适当取模
- 考虑到各节点的负载平衡,引入虚节点,每个物理节点对应为k各虚节点(k多大?),各个虚节点的hash值计算就分不同方法:
- key多大?兼顾计算效率和负载均衡性,因为节点数提前无法预估,可能要选择一个更好的经验值
- 引入k个hash函数,hash1(key), hash2(key), hash3(key)….hashK(key),分别设置到hash环上
- 针对key,构造key_1, key_2, key_3..,keyK,使用同一个hash函数分别计算上述key的hash,并在hash环上设置其节点信息
- TODO 这里的计算方式的选择,虚节点数多大(过少还是会不均衡),过大计算效率慢(多次计算hash),另外多个hash还是构造多个key也可能会影响到负载的均衡性,需要针对性的测试。
- 现在有个请求,比如用玩家userid作key,hash(key)得到值之后,因为一致性hash环是个首尾相接的有序数组实现的,可通过二分查找(查找第一个大于等于该
hash(key))的节点,复杂度O(logn)
一致性hash,对于带权重的也能支持到:比如a机器比b机器性能高一倍,希望其处理两倍于b的请求,那么就可以让a机器的虚节点多一倍。但是如果管理的节点数量成千上万之后,hash环上存储这些虚节点的开销就不能忽略了。
一致性hash替代方案:Rendezvous hashing
Rendezvous hashing,也叫Highest Random Weight hashing。它比一致性hash提出来早一年,用了一种不同的方式来解决余数hash中key remapping的问题,也能实现一致性hash中 “需要remmap的keys数量=k/n” 的这种效果。
它是怎么做的呢?将请求key和机器节点的key(比如ip),合在一起做hash(不像一致性hash那样分开做hash),然后选择hash值最大的那个机器节点。
type router struct {
endpoints []*Endpoint
}
func (r *router) Get(key string) *Endpoint {
var ep *Endpoint
hashVal := -INF for _, e := range r.endpoints {
h = hash(key, e)
if h > hashVal {
ep = e
hashVal = h
}
}
return ep
}
这种方案的最大问题是O(n)的计算复杂度,一致性hash是O(logn)查找复杂度,不过如果节点数不是很多的话,这个开销可以接受。
ps:测试了下,rendezvous hash到各个节点一次记load+1,那么100w请求时,各节点load负载标准差387,最大、最小节点负载占总负载(100w)比例为1/1000。
go-zero实现的经典的一致性hash算法,虚节点数量100个,默认的hash函数(不一致哈),100w请求时,各节点负载标准差1w+,最大、最小节点负载占总负载(100w)比例为5/100。
一致性hash变体:jump consistent hash
相比传统的环形一致性哈希,空间复杂度更低,根本无内存占用,而且算法非常简洁,C++的实现不到10行代码就可以搞定。
int32_t JumpConsistentHash(uint64_t key, int32_t num_buckets) {
int64_t b = -1, j = 0;
while (j < num_buckets) {
b = j;
key = key * 2862933555777941757ULL + 1;
j = (b + 1) * (double(1LL << 31) / double(key >> 33) + 1);
}
return b;
}
但是jump consistent hash存在它的局限性,使用场景受限:
- 服务器名不是任意的,而是按照数字递增,它更适合应用于数据存储场景,如随着时间增长、数据量变化有创建出更多的shards之类的场景。
- jump consistent hash只能在节点列表末端增加、删除节点,不能从中间任意删除节点,所以才说它适合用于存储类场景,比如数据容量大了,我们增加一个shard,或者说一个中间的shard崩溃了我们通过replicas复制来应对等。
在rpc场景下,后面任意一个节点都可能故障,我们需要从节点列表中删除任意一个节点的灵活性,所以说jump consistent hash不适用。
一致性hash变体:consistent hash with bounded load
这里的bounded load是啥意思呢?也是为了保证集群中各个节点的负载相对均衡,怎么做到呢,一个简单的思路就是:返回一个可以处理这个key的负载还ok的节点。
1. 返回一个能处理这个key的节点,怎么理解呢?
还是根据经典一致性hash的思路,计算key的hash从一致性hash环上找到第一个>=这个hash的虚节点,然后找到对应的物理节点信息。按经典一致性hash算法,此时就准备返回了。但是这里的方案变体还有其他事情要考量。
ps:在这个方案变体,一致性是要考虑的,但是负载均匀也是要考虑的,而且重视程度更重。经典一致性hash算法中,无论我们怎么设置虚节点数量、选择hash函数,包括给性能高的物理节点分配更多看似合理的虚节点等等。总有可能会出现负载不均衡的情况,负载均衡是一个理想值。我们在跑测试的时候也可以看到节点的最大、最小负载(hash一次load+1)相差很明显。怎么针对负载做优化呢?
2、如何做到负载相对均匀?
假设我们规定,返回一个节点时更新这个节点的load(load+1)、同时更新总的totalload,这样我们就能计算各个节点的avg load。如果第一步中待返回的load超过了avg load,我们就不返回该节点,而是从当前hash环当前虚节点位置继续向下遍历,直到找到下一个负载小于avg load的节点。
有没有两全其美的方案?
简单对比下,经典的一致性hash 及 jump一致性hash:
- ring-based consistent hash,以较大内存为代价,提供了增删任意node的灵活性,但是呢它的负载不够均衡。经典的实现里各个节点的负载是有偏差的,这给我们进行系统容量评估带来了些挑战,除非我们把虚节点加大,比如1000、2000。
- jump consistent hash,以极低的内存消耗,提供了高效的负载均衡,负载均衡均匀性也比较好,但是损失的是灵活增删节点的灵活性,这导致它在存储类shards路由场景中比较适用,其他场景则不适用。
那有没有两全其美的方案呢?(实际上没有)
- Multi-Probe Consistent Hash(简写为MPCH),就是为了解决这里的问题的,也是google提出的。
- 优点:它支持O(n)的空间复杂度(胜过ring-based一致性hash),支持O(1)的插入、删除时间复杂度(胜过jump一致性hash),支持增删任意节点(胜过jump一致性hash)
- 缺点:它的查询复杂度下降了,假设我们追求的均匀性,比方说负载的peak-to-mean为1.05%,那么需要做21轮hash(有公式可以算,略), 达到相同负载偏差,ring-based一致性hash需要700*ln(n),n为100个节点时hash环存储时就要1m内存。
- Maglev Hash方案,Maglev是google的网络负载均衡器,内部也用了一致性hash方案,我们简称maglev hash方案。maglev在google类似我司tgw这层,通过vip转发外部数据包给内部服务器时,希望尽量复用以前的tcpconn并在后端节点变化时做最少机器迁移:
- 优点:和ring-based一致性hash和rendezvous hash方案比,有不错的低内存开销、查询速度
- 缺点:maglev hash依赖一张查询表,当后端节点出现失败时构建这个查询表开销比较大,这也限制了后端节点的最大数量。
我们期望的完美的hash方案应该是什么样的?
调研了这些hash方案后,我们希望有这样的完美的hash方案:
- Only 1/n percent of the keys would be remapped on average where n is the number of nodes.
- A O(n) space complexity where n is the number of nodes.
- A O(1) time complexity per insertion/removal of a node and per key lookup.
- A minimal standard deviation to make sure that a node is not overloaded compared to another one.
- It would allow associating a weight to a node to cope with different node sizing.
- It would allow arbitrary nodes name (not numbered sequentially) to support both load balancing and sharding.
但是实际情况是,没有这样完美的hash方案!
- Rendezvous has a linear time complexity per lookup.
- Ring consistent hash has a poor minimal standard deviation without the concept of virtual nodes. With virtual nodes, is space complexity is O(n*v) with n the number of nodes and v the number of virtual nodes per node.
- Jump consistent hash does not have a constant time complexity and it does not support arbitrary nodes name.
- Multi-Probe Consistent Hash也存在问题,虽然空间、时间、灵活性不错,但是查询效率大大下降了
其实还有很多hash方案,它们都极力去平衡“一致性”和“均匀性”,但是实际情况就是没有完美的可以适用于所有场景的方案,下面是个hash方案的对比(展示了随着shards数增加查询的耗时 nanoseconds):
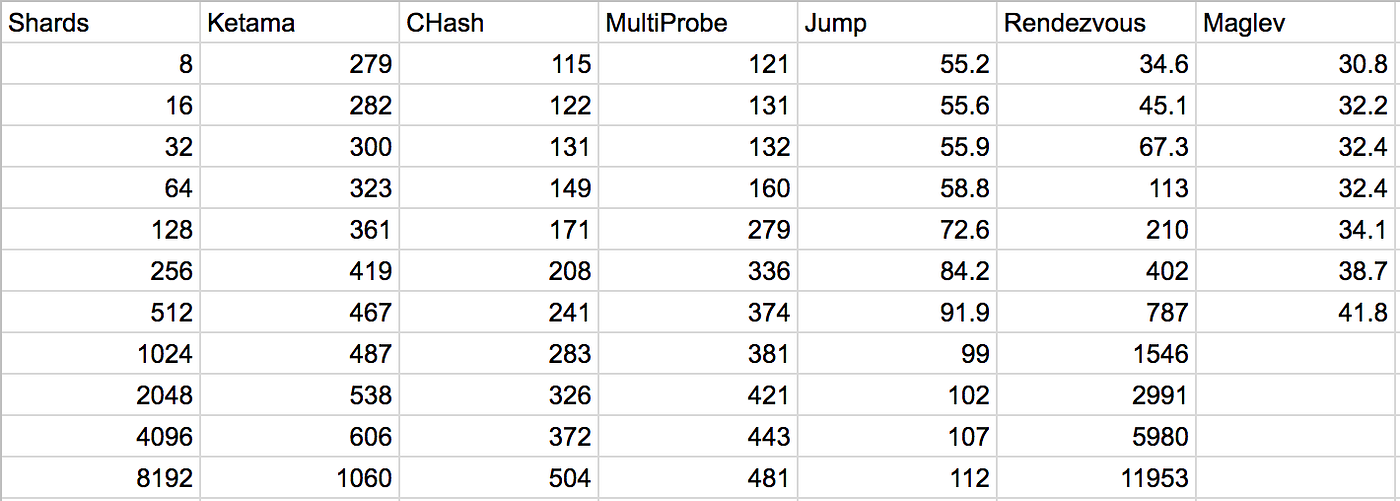
除了单次查询耗时,其实还需要考虑内存开销、构建开销、插入删除节点开销、最大支持节点数等,没有完美的方案。
所以,我们只能结合实际场景进行各种“权衡”,这也是为什么一致性hash方案尽管负载偏差比较差,但是它目前仍然应用范围比较广的原因,因为它对大多数场景都还ok。
## 负载均衡最大努力交付
现在回到我们现在的mesh框架的负载均衡场景,我们再重新评估下我们关切的点:
- 节点选择的一致性
- 节点负载的均匀性
- 尽最大努力交付
现在只考虑ring-based一致性hash方案,它好理解、适用范围更广,而且可以结合ring值域、key值域、虚节点数、hash函数选择来做些优化来满足需要:
- 一致性:根据理论值如果节点数n,那么新加入一个节点最多迁移1/n
- 均匀性:通过增加虚节点数量,hash函数也比较好,那么也可以改善均匀性,且能在我们接受范围内,ring占用的内存空间在可接受范围内
- 尽最大努力交付:如果选中的一个节点,是一个失败的节点,我们可以借助重试(replication),使用hash环选择第2个或更多个节点出来供使用,howto?
ring-based一致性hash,最大努力交付howto?
- 比如,hash出的一个节点,是一个失败的节点,直接取hash环上这个节点的下一个节点(不能是相同的物理节点),这种好实现点,虚节点记录下在环上的位置即可
- 比如,借鉴一些存储系统replication的思路,允许取出多个节点
参考资料
参考文献:
- 介绍一致性hash,https://itnext.io/introducing-consistent-hashing-9a289769052e
- redezvous hash,https://medium.com/i0exception/rendezvous-hashing-8c00e2fb58b0
- 经典一致性hash算法paper:Consistent Hashing and Random Trees: Distributed Caching Protocols for Relieving Hot Spots on the World Wide Web
- jump一致性hash算法paper:A Fast, Minimal Memory, Consistent Hash Algorithm
- jump一致性hash算法paper推导:https://zhuanlan.zhihu.com/p/104124045
- 一致性hash算法tradeoff:https://dgryski.medium.com/consistent-hashing-algorithmic-tradeoffs-ef6b8e2fcae8
- Multi-Probe一致性hash算法:https://arxiv.org/abs/1505.00062
- 一致性hash方案tradeoffs:https://itnext.io/introducing-consistent-hashing-9a289769052e
- Maglev hash方案,https://blog.acolyer.org/2016/03/21/maglev-a-fast-and-reliable-software-network-load-balancer/
实际应用:
- dapr采用了google consistent hash with bounded load, https://cloud.tencent.com/developer/article/1799300?from=article.detail.1340095
- go-zero rpc框架采用了经典的一致性hash算法
- twitter eventbus采用了rendezvous hash (最大随机权重hash)
- memcache client采用了jump consistent hash, https://sourcegraph.com/github.com/grafana/loki/-/blob/pkg/storage/chunk/cache/memcached_client.go?L100
- go-redis client默认采用了rendezvous hash,https://sourcegraph.com/github.com/go-redis/redis@v8/-/blob/ring.go?L39
影响一致性hash评估结果的因素
我们主要关注负载均衡算法的 ”一致性“、”均匀性“ 这两点,我们的测试也围绕着这两点展开。为了使得测试更有价值,更有可信度,需要说明下接下来的测试方案。
影响各负载均衡算法测试结果的,可能有以下几点:
服务物理节点数,固定为10
- 涉及到一致性hash算法及其变体时,我们会分别对比虚节点数为5、10、20、50、100、1000时的数量(直观理解,虚节点越多越均匀,内存开销可能越大)
- jump一致性hash,虚节点数量对内存没影响,但是该算法使用场景受限于节点只add不减少的场景(如只增加shards的存储场景)
- rendezvous hash,非一致性hash,没有虚节点概念,但是时间复杂度从一致性hash的O(logn)变为O(n),当节点数很多时开销不可忽视
待测试的userid数量足够多(将userid mapping到物理节点上去处理),要远多于节点数,比如100w
待测试的userid生成算法是否均匀,go标准库rand.Int()默认的source是均匀的,我们用这个方法来生成userid
各基于hash的负载均衡算法采用的hash函数是否一致,在从key计算hash value时,不一致的hash函数可能会导致分布不均匀,这样会导致难以评估各类负载均衡算法本身的差异性 可以把常见实现的代码clone下来,统一调节下hash函数来验证下,控制变量下。
一致性hash算法中,虚节点对应的hash value的计算,为了平衡负载均匀和开销,通常虚节点数量n可调整,这种情况下就没法按照经典一致性hash算法中那样提供n个hash函数了 一般是对物理节点host做下处理,比如加前缀1、2、3或者后缀9、10、11后表示虚节点,然后再用同一个hash函数做计算。 这种做法是否能让各个虚节点在ring上分布均匀呢?这个跟hash函数有关,但是直观感受是不见得能均匀。
用户userid在采用与hash(host)时相同的hash函数,userid的值域与其hash值,是否能在hash环上均匀分布呢?直观感受是,不见得。
上述这些都是影响我们评估算法质量的影响因素,在进行测试对比时要多关注。
另外,关于“一致性”方面,通过算法本身的理论描述是可以给出一个理论值的:
- 一致性hash,假设k个key,n个nodes,那么节点加入、离开后,需要remapping的key大约为k/n(均衡的前提下)
- 一致性hash with bounded load,这个虽然负载比较均衡,但是直观感受是“一致性”不如经典的“一致性hash”,因为它会在负载偏高时选择下一个节点
- jump consistent hash,这个算法只考虑存储场景data shards增加的情况,我们可以先延迟测试这个
- rendezvous hash,理论上来说,只要新加入的节点host不会导致hash(userid, host)最大,就对原来的userid没影响,但是有多少userid会受影响呢?待理解
但是实际使用时到底怎么样,就跟key本身以及hash函数选择的优劣很有关系了。
一致性hash实际测试结果
- 选择一个一致性hash实现,比如采用go-zero的一致性hash实现
- 测试一致性,这个有算法理论支撑,我们其实可以不用测试
- 测试均匀性,这个有必要亲自测试下
- 修改以支持最大努力交付,比如失败之后该如何重试,以go-zero中定义的一致性hash环为例:
- 先计算key从consistenthash.keys找到下一个虚节点的hashvalue,然后从ring[hashvalue]得到nodes,遍历这些nodes看是否有可用节点
- 上面不成,直接索引值+1顺着consistenthash.keys找下一个索引位置的hashvalue,再从ring[hashvalue]得到nodes,遍历看是否有可用节点,
- 如果转了一圈了还没有合适的,就应该退出了,当然也可以限制最大重试次数
- 另外要注意,之前遍历到的失败的节点,下次从虚节点找到对应物理节点时,应检查物理节点是否是已经排除过的,是的话就没必要重试了。
go-zero中一致性hash实现源码阅读
定义
type ConsistentHash struct {
hashFunc Func
replicas int
keys []uint64
ring map[uint64][]interface{}
nodes map[string]lang.PlaceholderType
lock sync.RWMutex
}
- hashFunc是自定义的hash函数
- replicas表示每个物理节点对应的虚节点数量
- keys其实就是一致性hash环的表示,记录了虚节点对应的hash值,有序
- ring其实是hash值到一组虚节点的映射,它其实是为了解决hash冲突来的
- 准确地说,keys+ring构成了一致性hash环,查找hash(key)对应的虚节点时,先在keys中找到>=hash(key)的虚节点对应的hash值,
- 然后,通过hash值到ring中找对应的虚节点
- 因为可能有冲突,所以map[k]v这里的v是一个slice
- nodes中记录了当前添加了哪些物理节点,但是这里的map[k]v,k是节点描述信息,可以简单理解成node.String(),v是struct{}
这个一致性hash的设计还是不错的。
Add/AddWithReplicas/AddWithWeight
添加新节点的时候,大致就是这几个函数,逻辑是什么呢?
- 先获取待添加节点的一个描述信息,如String(),然后记录到nodes中,表示记录了这个节点
- 然后呢,根据设置的虚节点数量,for循环,每次在描述信息后面添加数字后缀,计算hash,然后记录到keys、ring里面 前面提过了,keys+ring共同构成了一致性hash环
Get
根据key获取节点的时候呢?
- 先计算key的hash,然后从keys中找第一个>=hash(key)的位置,这个位置对应的hash即为候选虚节点的hash,
- 然后通过虚节点的hash去ring里面找,ring里面是个slice,是为了解决散列冲突的,
- 怎么从这个slice中取呢,重新hash一次,从这个slice里面选一个
继续优化
ring-based一致性hash的均匀性还可以继续优化,比如从hash函数的选择方面,虚节点数量的选择方面。
以下是10个物理节点,均匀的100w userid,在不同虚节点数量、hash函数选择情况下的测试情况:
case: replicas:50+hash:murmur3.Sum64 标准方差: 14628.560790453721 max: 126737 min: 76395 (max-min)/times: 0.050342 peak/mean: 1.26737
case: replicas:100+hash:murmur3.Sum64 标准方差: 14555.295022774357 max: 127129 min: 76438 (max-min)/times: 0.050691 peak/mean: 1.27129 *
case: replicas:200+hash:murmur3.Sum64 标准方差: 6902.00454940447 max: 110178 min: 85121 (max-min)/times: 0.025057 peak/mean: 1.10178
case: replicas:500+hash:murmur3.Sum64 标准方差: 2285.3205902017335 max: 105277 min: 97136 (max-min)/times: 0.008141 peak/mean: 1.05277
case: replicas:1000+hash:murmur3.Sum64 标准方差: 2069.765928794848 max: 104603 min: 97606 (max-min)/times: 0.006997 peak/mean: 1.04603
case: replicas:2000+hash:murmur3.Sum64 标准方差: 2618.900303562547 max: 104628 min: 94870 (max-min)/times: 0.009758 peak/mean: 1.04628
case: replicas:50+hash:xxhash.Sum64 标准方差: 8627.559643375409 max: 119229 min: 91110 (max-min)/times: 0.028119 peak/mean: 1.19229
case: replicas:100+hash:xxhash.Sum64 标准方差: 8918.29840272235 max: 120236 min: 90692 (max-min)/times: 0.029544 peak/mean: 1.20236 *
case: replicas:200+hash:xxhash.Sum64 标准方差: 5913.828556865679 max: 111947 min: 89811 (max-min)/times: 0.022136 peak/mean: 1.11947
case: replicas:500+hash:xxhash.Sum64 标准方差: 4256.551350565384 max: 107631 min: 93326 (max-min)/times: 0.014305 peak/mean: 1.07631
case: replicas:1000+hash:xxhash.Sum64 标准方差: 3148.5766943176086 max: 106134 min: 95150 (max-min)/times: 0.010984 peak/mean: 1.06134
case: replicas:2000+hash:xxhash.Sum64 标准方差: 1664.1786562746202 max: 103375 min: 96885 (max-min)/times: 0.00649 peak/mean: 1.03375
case: replicas:100+hash:crc32.ChecksumIEEE 标准方差: 16188.201024202783 max: 121890 min: 69629 (max-min)/times: 0.052261 peak/mean: 1.2189
case: replicas:200+hash:crc32.ChecksumIEEE 标准方差: 11440.727826497754 max: 126050 min: 82970 (max-min)/times: 0.04308 peak/mean: 1.2605 *
case: replicas:500+hash:crc32.ChecksumIEEE 标准方差: 17259.726985094523 max: 130659 min: 69507 (max-min)/times: 0.061152 peak/mean: 1.30659
case: replicas:1000+hash:crc32.ChecksumIEEE 标准方差: 21791.261533009052 max: 137256 min: 72892 (max-min)/times: 0.064364 peak/mean: 1.37256
case: replicas:2000+hash:crc32.ChecksumIEEE 标准方差: 12953.256825987819 max: 120299 min: 73664 (max-min)/times: 0.046635 peak/mean: 1.20299
不难看出: xxhash的均匀性首先比较好,在100个虚节点(这个一般是比较常用的经验值)时,最大最小负载偏差2.9%,peak/mean比为1.20
总结
本文从一致性hash负载均衡策略触发,深入了解了下不同的方案变体,最后针对普适应更好的一致性hash方案、go-zero实现、实践中的引用改进进行了探索介绍。