Netflix自适应过载保护算法
Posted 2023-04-18 23:38 +0800 by ZhangJie ‐ 1 min read
思路简介
Netflix/concurrency-limits,基于Java实现的,star 2.9k+,也有go语言的第三方实现platinummonkey/go-concurrency-limits。
平时大家评估服务负载、容量、最佳qps是如何做的,往往是先压测看服务能抗多少qps,然后请求方取个75%*qps作为一个阈值,然后请求方通过令牌桶、漏洞之类的来进行控制。但是对于很多个节点、需要动态扩缩容场景,这个固定值很快就会失效……当然有分布式频控的搞法……netflix的思路是与其将重点放在如何告知客户端设置qps,还不如让客户端能根据rtt自动算出下阶段的最大请求量来,这个是借鉴了little’s law以及tcp的拥塞控制。
- 它这里vegas算法估计的limit是这么算的 L * (1-minRTT/sampleRTT),
- 然后还有个gradient2优化,来平滑下
详细设计
这个库提供了很多的limiter实现:
fixed,固定值,并发请求的时刻量不能超过这个fixedlimiter的值,这个值不变
aimd,基于loss的,请求成功就加性增,遇到失败就乘性减
windowed,基于滑动窗口实现的,每个窗口期内有一个limiter(成员delegate),可以是前面提到的fixed、aimd等limiter
vegas,是基于测量的rtt的,另外也会考虑丢包。它实际上是确定了这么几个负载阶段:请求没有排队、请求有少量排队、请求有多一点排队、请求有很多排队。每次采样后会更新最新的limit,更新时会首先根据当前minRTT和sampleRTT以及当前limit来算一下接下里的queueSize,然后检查queueSize处于上面哪个阶段,然后使用对数操作进行平滑对当前的limit进行增大、缩小的调整。
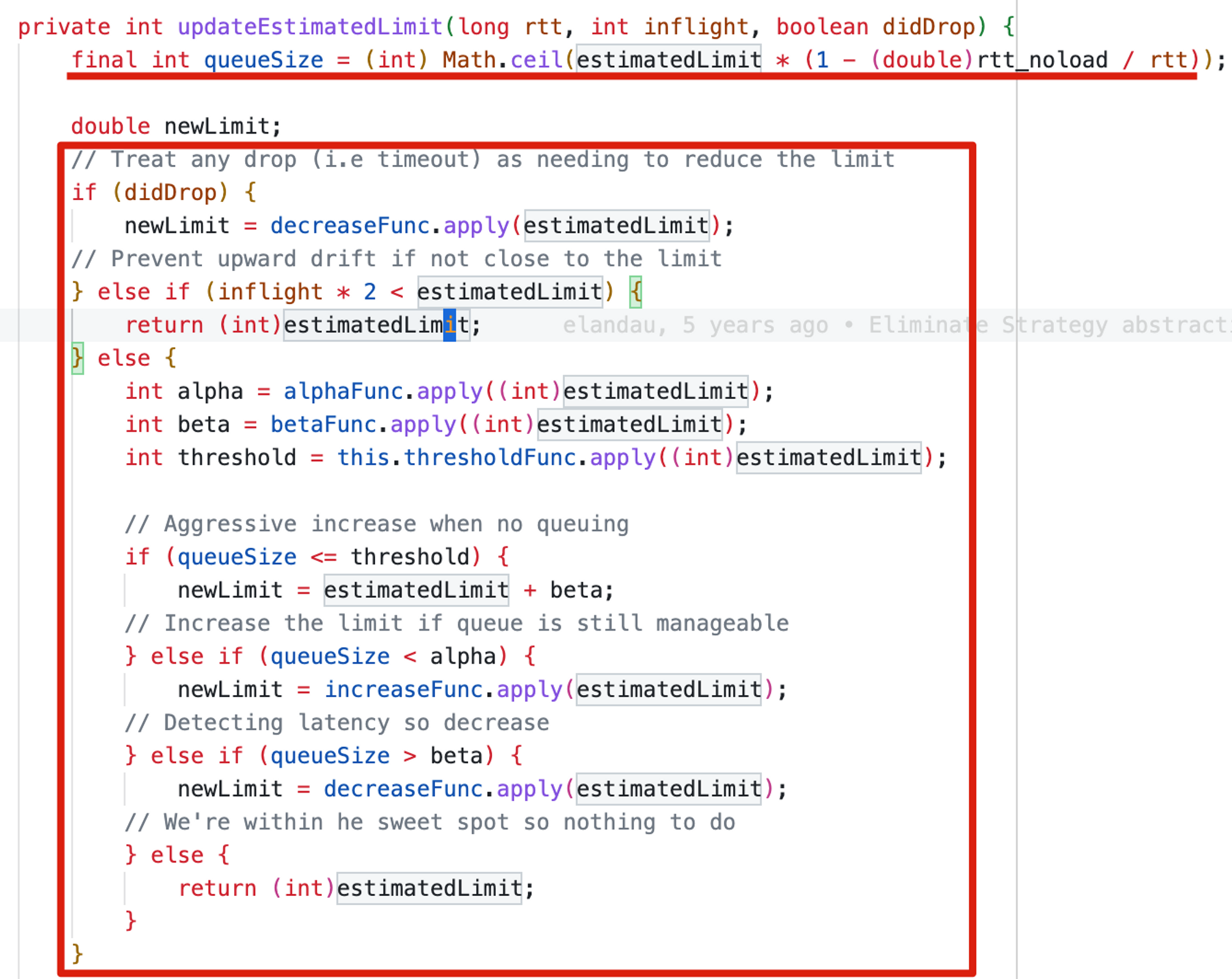
gradient,它这里和vegas的实现思想上是一致的,只是对于inflight*2≥estimatedLimit时的处理逻辑不一样,vegas是将排队严重情况分成了几个阶段用不同的函数来调整limit,gradient是用了一个“梯度”的方法来调整,大致上是当前estimatedLimit * gradient + queueSize…这个算法的平滑处理能理解,但是不是那么“想象“象其效果。
仔细看下,多揣摩几遍还是可以想象的出来的 😂
gradient2,它这里是对gradient的一个优化,什么优化呢?gradient是基于测量minRTT的,这会有个问题,minRTT还是比较敏感的,对于测量tcp的包(因为通常都会分片、分片大小往往都是确定的)没啥问题还挺好的。
但是使用minRTT来测量RPC就不是特别好,因为RPC请求,不同接口的请求可能大小变化挺大的,即使是相同接口的请求可能变化也比较明显的。所以使用avgRTT要比minRTT更友好些,不至于limit的“抖动”,可能会导致过度的load shedding,造成不必要的请求被拦截。
然后这里的avgRTT怎么算呢?从开始到现在的请求RTT的平均值?这里其实用的一个指数平均,一方面有平均值的作用能避免minRTT的上述问题;另一方面,使用的指数平均,0.8longtermRTT + 0.2sampleRTT,这样也能尽可能反映当前时刻的负载信息。
另外这里的tolerance=2.0是说,如果遇到sampleRTT=tolerance*longtermRTT时,可以容忍这么长耗时的请求而不降低limit,仍然可以按照原速率发送,如果超了tolerance下的设置,那么梯度gradient就会小于1.0,此时limit就会被调低。limit调低时也会被smooth参数进一步平滑下。
当从过载中恢复时,因为longtermRTT也被搞大了,如果不加处理,可能会有较长一段时间才能恢复到≤sampleRTT,这会有个问题,如果不能尽快恢复longtermRTT,则有可能持续增加发包速率再次导致过载。为了尽快恢复longtermRTT到正常值让发包速率处于steady状态,会判断
longrtt / shortrtt>2时会给longrtt*0.95尽快调低longrtt。

调查总结
总结一下,vegas、gradient都是基于minRTT进行测量的,对于RPC场景而言可能并非最佳选择。相比之下gradient2是基于longtermRTT指数平均代替了minRTT,对RPC场景适应性可能更好。
除了RTT,它们都考虑了负载steady、overload情况下的不同阶段以及调整策略(主要是increase limit、decrease limit时如何做到平滑)。可以测试下gradient2先有个直观认识。
一点后话
当你的系统是一个大型的分布式系统,集群也需要动态扩缩容,系统中的负载类型不同,同一个服务的不同接口处理耗时不同,即便是相同接口不同请求处理耗时也有明显不同,这个时候常规的基于“请求配额”的传统过载保护机制是不怎么有效的。
最初有这种想法,是在看点做内容处理链路的时候,注意到有些服务是计算密集型的(如OCR模块),有些是IO密集型的,有些图文发表请求里面只有一张图片,有的有多张图片,有的文章比较短,有的文章比较长,这都会影响你的系统负载、处理耗时,如何科学的评估负载进而确定合理的请求配额,是一件比较困难的事情。
后面开始思考如何评估“负载”这样的问题,可能会想CPU使用率、内存使用率高、IO利用率高、网卡利用率高,实际上不同workload类型对资源的使用情况不同,这些指标高还真不一定就是负载高。如果涉及到具体语言,可能会去想Java、Go GC STW问题……
预期纠结这些,不如更高屋建瓴地站在宏观角度看看,如果负载高了会发生什么?系统负载开始变高之后,是可以把其当做一个黑盒通过外部观测来观察出来的。Netflix的过载保护算法正是从这里触发,看似简单的实现,但是并不是不着边际。整个网络世界得以正常运转的TCP拥塞控制也是建立在RTT、Loss观测基础上的,Netflix也将其Vegas Limiter命名成了Vegas,正是因为它借鉴了TCP vegas拥塞控制算法(TCP Reno的替代算法)。