Linux性能问题排查60s
Posted 2023-09-08 16:30 +0800 by ZhangJie ‐ 7 min read
简介
最近在阅读Gregg大佬著作《BPF Performance Tools》,其中一小节作者提到了其在Netflix工程团队中践行的一个性能排查checklist,当遇到Linux性能问题时,前60s往往是借助这个checklist来进行排查,如果有必要,缩小范围后再借助其他工具进行进一步排查。我觉得这个简短的checklist还挺实用的,特地摘录出来分享下。
问题背景
这个checklist可以用来指导排查任意Linux性能问题,当我们知道有台机器性能(疑似)有问题时,我们就可以登录这台机器,按照这个checklist来进行前60s的快速分析。这也是Gregg自己以及Netflix工程团队实践中总结出来的。
对于很多刚入行后台开发的同学而言,我觉得这个还是比较有价值的,应该在日常工作中不断实践、不断加深对性能影响因素的理解。有位技术扎实的同事曾经这样说,一切都是可计算的、可量化的,比如判断对特定工作负载瓶颈是什么,cpu、内存、网卡?链路长短,网络延迟,然后大致的系统吞吐量是什么样的?他大致就能推算出来。
其实,Jeff Dean曾经在论文里给出过一些开发人员应该知晓的latency数据:
L1 cache reference ......................... 0.5 ns
Branch mispredict ............................ 5 ns
L2 cache reference ........................... 7 ns
Mutex lock/unlock ........................... 25 ns
Main memory reference ...................... 100 ns
Compress 1K bytes with Zippy ............. 3,000 ns = 3 µs
Send 2K bytes over 1 Gbps network ....... 20,000 ns = 20 µs
SSD random read ........................ 150,000 ns = 150 µs
Read 1 MB sequentially from memory ..... 250,000 ns = 250 µs
Round trip within same datacenter ...... 500,000 ns = 0.5 ms
Read 1 MB sequentially from SSD* ..... 1,000,000 ns = 1 ms
Disk seek ........................... 10,000,000 ns = 10 ms
Read 1 MB sequentially from disk .... 20,000,000 ns = 20 ms
Send packet CA->Netherlands->CA .... 150,000,000 ns = 150 ms
有开发者将上述数据进行了可视化,以方便从视觉上更直观的感受差别:
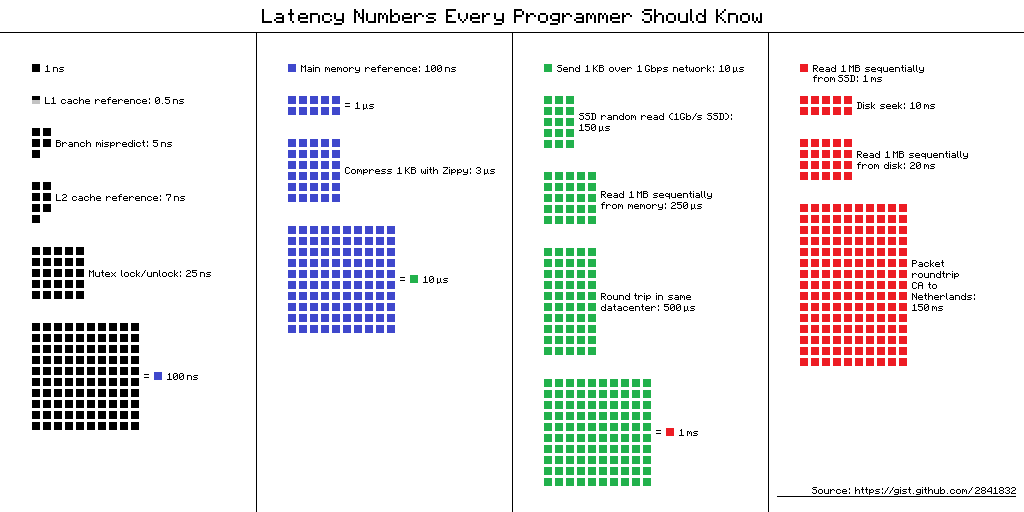
如果一直关注性能领域,实践一段时间后就大约能摸到门道了,还是很有帮助的。当我们遇到性能方面的问题后,经验会帮助我们更快速地认识到哪些地方可能出了问题,排查反而可能只是印证思路的过程。
我们今天重点讨论对于任意Linux性能问题(可能也不是熟悉的系统),应该如何排查的问题,尤其是最开始的60s应该如何快速定位缩小问题域。
Linux 60s分析
这个checklist不是一个大杂烩,不是列举一堆工具,它是工程团队沉淀的经验。
- uptime
- dmesg | tail
- vmstat 1
- mpstat -P ALL 1
- pidstat 1
- iostat -xz 1
- free -m
- sar -n DEV 1
- sar -n TCP,ETCP 1
- top
下面一个个解释下其输出的含义,以及可以帮助确定哪些问题。
uptime
$ uptime
17:07:46 up 18:27, 0 users, load average: 0.08, 0.02, 0.01
uptime可以查看机器上线时间、平均负载的变化,看性能问题主要是看平均负载的变化。load average有3个值,从左到右分别表示最近1min、5min、10min的负载变化,因此可以看出最近一段时间的负载是上升、下降还是持平。
如果看到15min负载是比较高的,但是最近1min负载比较低或者正常,说明负载已经降下来了,我们登录机器太晚了。一般企业会考虑容错,出问题的机器会被自动剔除掉。如果需要进一步分析,就需要借助其他办法来排查了,比如时光机atop或其他性能观测平台。
负载,指的是待调度执行的进程数(包括可运行和陷入不可中断睡眠的进程)。因此,如果数值超过cpu核数时就可能意味着cpu饱和了。
dmesg | tail
如果进程使用内存超过限制,或者机器整体内存紧张而oom killer选中了该进程被kill掉的话,其log信息会写入系统日志中,可以直接cat /var/log/messages查看,也可以通过dmesg来查看。
对于一个拥有64GB机器的我来说,想要轻松复现一个oom kill的demo,还需要思考下。ulimit -v, ulimit -m, control group限定内存大小,不知道为何,这几个方法并不会直接导致oom killer介入并杀死进程,跟它们之间的工作机制有关系,暂不讨论。
启动一个容器 docker run -it --rm -m 100m golang:latest /bin/bash,里面写一个go,通过选项-m 100m限定了容器中所有进程的最大内存上限。启动后写一个go程序,循环分配内存并提交,如:
func main() {
for {
b := make([]byte, 1<<20)
b[0] = 1
}
}
编译并关闭GC运行:
$ GOGC=off ./app`
Killed
容器就是普通进程,只不过是通过Linux namespaces+controlgroup等进行了一些列的隔离、控制,在宿主机上运行dmesg | tail就可以看到进程被kill的信息。
$ dmesg | tail
[69826.948539] [ 23658] 0 23658 3594 754 69632 344 0 bash
[69826.948799] [ 23882] 0 23882 1260354 22707 8851456 25101 0 main
[69826.949060] [ 23908] 0 23908 14443 619 147456 134 0 top
[69826.949335] oom-kill:constraint=CONSTRAINT_MEMCG,nodemask=(null),cpuset=93a579dd93754105f6650187e2ba12e40911e028bd01ce85e24277e59166e3c8,mems_allowed=0,oom_memcg=/docker/93a579dd93754105f6650187e2ba12e40911e028bd01ce85e24277e59166e3c8,task_memcg=/docker/93a579dd93754105f6650187e2ba12e40911e028bd01ce85e24277e59166e3c8,task=main,pid=23882,uid=0
[69826.950308] Memory cgroup out of memory: Killed process 23882 (main) total-vm:5041416kB, anon-rss:90828kB, file-rss:0kB, shmem-rss:0kB, UID:0 pgtables:8644kB oom_score_adj:0
[70504.061676] docker0: port 1(veth791efaa) entered disabled state
[70504.062119] veth39cc165: renamed from eth0
[70504.195179] docker0: port 1(veth791efaa) entered disabled state
[70504.197296] device veth791efaa left promiscuous mode
[70504.197814] docker0: port 1(veth791efaa) entered disabled state
对于有些进程跑着跑着不见了,可以优先考虑是不是oom kill了,dmesg就是个好办法,它能输出进程被kill时的一些信息,如内存使用量之类的。
Linux如何选定一个进程进行oom kill可以详细了解下这背后的决策过程,不完全不严谨的可借鉴的总结就是,整机内存紧张,如果某个进程运行时间不久但是占用内存高,其oom score分值就越大,越大的越容易被kill。时光机atop也可以看到进程被kill的信息。
vmstat 1
zhangjie@PC-GeniusStation gotest $ vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 2476 26154180 577756 4476564 0 0 2 9 3 11 0 0 100 0 0
0 0 2476 26154184 577756 4476564 0 0 0 0 28 766 0 0 100 0 0
0 0 2476 26154184 577756 4476564 0 0 0 52 21 738 0 0 100 0 0
vmstat表示虚拟内存统计细腻系,参数1表示1s钟打印一次统计信息。比较有参考价值的几列数据:
r:正在运行的进程数+可运行等待执行的进程数,不包含等待IO的进程数,这个值比top和uptime总的load average更能反映CPU的饱和情况,因为它不包含IO进程,这样如果这个值比真实CPU核数多的话,那就说明CPU饱和了。
free:空闲内存数量,单位KB,使用
free -m可以以mb为单位显示。si, so:swap-in、swap-out数量(换入、换出次数),如果这些值不是0,意味着内存不足了,因为换入、换出仅在内存不足时才会发生。注意这里的换入换出是虚拟内存层面的。以前RAM比较小,经常有交换区的概念,现在RAM更大更便宜了,用的就比较少了。比如以前4GB内存+320GB硬盘配置下经常建个4GB大小的swapfile,现在我机器光RAM就是64GB 😄
ps:磁盘数据加载到内存,先是触发pagefault,然后内存控制器捕获异常后交给内核进行pages加载,也有叫法叫换入。注意这些术语所指的区别。
us, sy, id, wa, st:这几个是将cpu时间进行了细化,分别表示用户态、内核态、空闲时间,以及io等待时间,被某些虚拟机或者Xen等虚拟化技术抢走的时间。
通过这里的数据可以看出大部分时间都是消耗在us(用户态),要进一步分析,就需要借助其他工具、方法,如go tool pprof对程序进行分析,可以通过cpu火焰图观察到不同代码时间占用情况。
mpstat -P ALL 1
$ mpstat -P ALL 1
Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
Average: all 3.14 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 96.86
Average: 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: 1 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
...
Average: 22 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
...
Average: 30 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
Average: 31 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00
mpstat能够输出所有CPU核心的耗时,而且它当这个耗时在不同状态下的时间占比进行了区分,比如usr,sys,iowait,irq,soft,steal。
在上图中,我们看到有个核心core-22的user占比为100%,说明很可能存在一个单线程程序存在cpu瓶颈。
假设,iowait时间占比较高,就要考虑disk io是否存在瓶颈;如果sys时间占比过高,则可以借助syscall、kernel tracing、cpu profiling工具进行进一步分析。
pidstat 1
Linux 5.15.90.1-microsoft-standard-WSL2+ (PC-GeniusStation) 09/08/2023 _x86_64_ (32 CPU)
06:45:10 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:45:11 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:45:12 PM 1000 11479 1.00 0.00 0.00 0.00 1.00 22 pidstat
06:45:12 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:45:13 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:45:14 PM 1000 11480 65.00 0.00 0.00 0.00 65.00 22 main
06:45:14 PM UID PID %usr %system %guest %wait %CPU CPU Command
06:45:15 PM 1000 11480 100.00 0.00 0.00 0.00 100.00 22 main
pidstat能显示每个进程的cpu使用情况,也会将cpu使用时间细化成user,system,guest,wait,和top不同的是,它显示的是随着时间推移进程cpu使用率情况发生变化的信息,不变化的就不输出了。
上面这个例子显示有个pid=11480的进程,它的cpu使用率逐渐从1%上升了65%,又上升到了100%。因为这里我写了一个死循环的程序来测试。
iostat -xz 1
$ iostat -xz 1
Linux 5.15.90.1-microsoft-standard-WSL2+ (PC-GeniusStation) 09/08/2023 _x86_64_ (32 CPU)
avg-cpu: %user %nice %system %iowait %steal %idle
0.04 0.00 0.03 0.00 0.00 99.93
Device r/s w/s rkB/s wkB/s rrqm/s wrqm/s %rrqm %wrqm r_await w_await aqu-sz rareq-sz wareq-sz svctm %util
loop0 0.04 0.00 3.30 0.00 0.00 0.00 0.00 0.00 0.79 0.00 0.00 92.27 0.00 0.29 0.00
loop1 0.02 0.00 1.60 0.00 0.00 0.00 0.00 0.00 0.21 0.00 0.00 70.95 0.00 0.42 0.00
loop2 0.06 0.00 4.02 0.00 0.00 0.00 0.00 0.00 0.23 0.00 0.00 71.93 0.00 0.37 0.00
sda 0.02 0.00 0.99 0.00 0.01 0.00 28.05 0.00 0.16 0.00 0.00 64.08 0.00 0.66 0.00
sdc 1.85 0.49 30.38 18.33 0.35 1.62 15.84 76.73 0.14 5.17 0.00 16.40 37.28 0.67 0.16
sdb 0.01 0.01 0.07 1.46 0.00 0.36 26.15 97.29 1.01 1.35 0.00 8.56 147.50 2.96 0.01
sdd 0.01 0.24 0.61 245.70 0.00 0.06 4.82 20.85 0.31 0.81 0.00 51.18 1010.66 4.47 0.11
sde 0.42 0.09 14.12 1.02 0.16 0.16 27.21 64.33 0.17 5.39 0.00 33.34 11.27 0.25 0.01
avg-cpu: %user %nice %system %iowait %steal %idle
3.12 0.00 0.00 0.00 0.00 96.88
这个工具显示的事存储设备的IO统计信息,输出的信息有点多、有换行的情况,其中值得关注的列:
- r/s, w/s, rkB/s, wkB/s:表示每s读请求数、写请求数、读数据量KB、写数据量KB。磁盘IO导致的性能问题,从这些很容易看出是读还是写导致的。
- await:平均IO等待时间,包括请求IO排队时间+IO服务时间,总之就是程序感受到的IO等待时间。如果该值比平均时间大的话,那么可能就有可能是设备IO饱和、设备出问题的征兆。
- avgqu-sz:发送给IO设备的平均请求数量,如果这个值明显大于1,就很可能表示是设备饱和的情况(但是有些设备,比如虚拟设备,它后面可能对应着多个磁盘,这个时候是因为并发请求多个磁盘,大于1是正常的)。
- util:设备利用率,表示设备繁忙程度,1s内设备有多长时间在执行IO任务,不是表示设备容量使用百分比。如果这个值超过60%就要警惕可能会导致比较差的性能,100%则表示设备饱和。
free -m
$ free -m
total used free shared buff/cache available
Mem: 31964 1479 24351 5 6134 30030
Swap: 8192 2 8189
这个工具大家应该比较熟,它能显示内存总量、已使用量、空闲内存的情况,几个大家可能不熟悉的提一下。
shared表示tmpfs的内存占用量,通常比较小,一般/run, /sys, /tmp, /dev/shm虚拟文件系统会使用tmpfs。
buff/cache表示kernel使用的buffer、cache大小,这部分内存在需要时可以回收给应用程序使用的,内核使用它们主要是为了改善性能。
ps:free命令输出中的buff/cache列显示的是被内核缓冲区和页面缓存所占用的内存量,它主要包括以下几类信息的缓存:
磁盘块缓存(disk cache):对磁盘IO进行缓存,避免每次从磁盘读取数据。这部分是文件系统对磁盘内容的缓存。
inode和dentry缓存:文件系统元数据的缓存,如文件名、索引节点数据等。避免查找元数据时总是访问磁盘。
目录缓存:目录文件内容。
进程执行代码的缓存:已执行的代码可以被缓存复用。
页面缓存:文件 mmap 到内存的页面缓存。
网络缓冲区:网络数据通过socket接收时的缓冲区。
键值对缓存:一些数据结构如散列表的缓存。
其他数据结构缓存:例如进程信息、文件描述符。
所以简单说,buff/cache列主要反映了内核对文件系统、磁盘内容、网络数据、元数据等各类数据的缓存占用内存量。这些缓存可以加速访问速度。
total=used+free+shared+buff/cache,available是一个估计值,表示当前有多少内存供应用程序使用。
sar -n DEV 1
$ sar -n DEV 1
Linux 5.15.90.1-microsoft-standard-WSL2+ (PC-GeniusStation) 09/08/2023 _x86_64_ (32 CPU)
07:32:46 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
07:32:47 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:32:47 PM eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:32:47 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
07:32:48 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:32:48 PM eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:32:48 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s %ifutil
07:32:49 PM lo 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
07:32:49 PM eth0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
sar工具有很多统计模式,网络、磁盘、cpu等等,这里是用来查看网络相关的数据。通过rxkB/s、txkB/s可以查看到网络收发速率,可以评估是否达到了网卡的瓶颈。
sar -n TCP,ETCP 1
$ sar -n TCP,ETCP 1
07:35:03 PM active/s passive/s iseg/s oseg/s
07:35:04 PM 0.00 0.00 0.00 0.00
07:35:03 PM atmptf/s estres/s retrans/s isegerr/s orsts/s
07:35:04 PM 0.00 0.00 0.00 0.00 0.00
07:35:04 PM active/s passive/s iseg/s oseg/s
07:35:05 PM 1.00 0.00 2.00 3.00
07:35:04 PM atmptf/s estres/s retrans/s isegerr/s orsts/s
07:35:05 PM 0.00 0.00 0.00 0.00 0.00
这里使用sar来查看TCP连接、TCP错误相关的数据,有这么几列:
- active/s:表示每s本地主动发起的tcp连接数量;
- passive/s:表示每s本地被动接受建立的tcp连接数量;
- retrans/s:表示每妙tcp重传次数;
主动连接数和被动连接数有助于对工作负载进行区分,重传表示存在网络问题或者远程主机问题。
top
$ top
top - 19:42:37 up 21:02, 0 users, load average: 0.00, 0.03, 0.32
Tasks: 15 total, 1 running, 14 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 0.2 sy, 0.0 ni, 99.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31964.6 total, 24348.5 free, 1479.7 used, 6136.4 buff/cache
MiB Swap: 8192.0 total, 8189.6 free, 2.4 used. 30030.2 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 2324 1712 1600 S 0.0 0.0 0:00.01 init(OracleLinu
4 root 20 0 3392 456 68 S 0.0 0.0 0:19.65 init
960 root 20 0 2340 112 0 S 0.0 0.0 0:00.00 SessionLeader
961 root 20 0 2340 120 0 S 0.0 0.0 0:00.00 Relay(962)
962 root 20 0 732512 27996 15856 S 0.0 0.1 0:02.83 docker-desktop-
979 root 20 0 2340 120 0 S 0.0 0.0 0:00.00 Relay(980)
980 zhangjie 20 0 769360 44228 27924 S 0.0 0.1 0:05.90 docker
1066 root 20 0 2340 112 0 S 0.0 0.0 0:00.00 SessionLeader
1067 root 20 0 2340 120 0 S 0.0 0.0 0:00.03 Relay(1068)
1068 zhangjie 20 0 22736 8288 3376 S 0.0 0.0 0:00.07 bash
15621 root 20 0 2340 112 0 S 0.0 0.0 0:00.00 SessionLeader
15622 root 20 0 2340 120 0 S 0.0 0.0 0:00.00 Relay(15623)
15623 zhangjie 20 0 22604 8096 3288 S 0.0 0.0 0:00.02 bash
16263 zhangjie 20 0 55416 4216 3588 R 0.0 0.0 0:00.00 top
18683 root 20 0 2348 120 0 S 0.0 0.0 0:00.83 Relay(18684)
top可以一次性显示性能相关的负载情况、cpu、内存相关的数据。到这里,top显示的很多数据,在前面提及的工具中我们已经见过了,但是运行top来二次确认下系统、进程数据也是有用的。
top有几个比较实用的操作,可能大家不清楚的,也提一下:
- h,按下h唤出帮助菜单;
- c,显示完整的cmd,包含路径几参数信息
- shift+m,按内存占用情况对进程列表进行排序
- e,切换内存占用量的单位,kb、m、g
- O,自定义key=value进行过滤,如COMMAND=bash
- 1,显示每个处理器核心的负载信息
- top -p
-H,可以显示每个进程下的线程信息
那,先执行top行不行呢,当然可以,实际上要定位到问题源头,你可能要把上述工具都跑一下,问题排查的过程就是一步步缩小问题范围的过程。
在理解上,我们可以接受这样的一系列工具,去逐个执行下看看情况,但是在实践中,我们还是希望有更好用的工具,比如atop,它能在同一个程序中展示上述工具所能显示的所有数据(atop也会调用上述工具,比如sar)。
Linux atop
atop被称作是Linux下的时光机,是因为它能定时借助sar等系列工具收集、统计、记录下系统的一些运行信息,比如某个时刻的负载情况、cpu、内存、网络、设备io等等的情况,甚至连oom kill这样的事件都会记录下来。
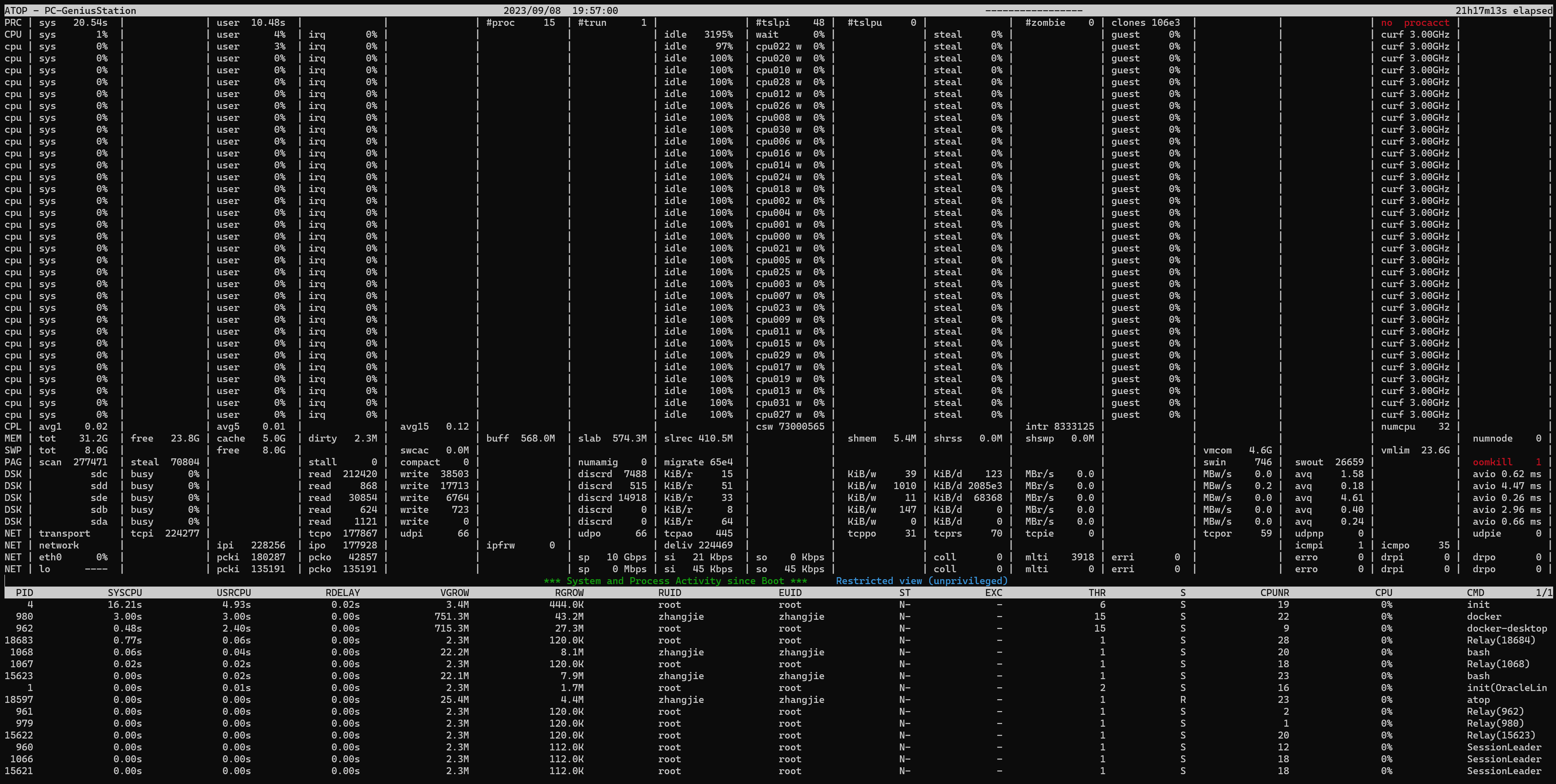
至于它为什么被称为时光机,是因为它真的是时光机:
- atop -r path-to/hhmmss.log,每天的运行时数据都会记录在一个日志文件里,你可以加载当天、过去的日志数据,来查看当时发生了什么;
- t: 可以将时间往后拨,按t一次,就会快进1min;
- shift+t:可以将时间往前拨,按shift+t一次,就会倒退1min;
- b:seek到指定时间对应的数据,如b 20230908 12:00,那么就查看12点以后的数据;
- …
- h:查看帮助菜单;
atop大而全,确实是一个让人喜欢的工具,但是它输出的信息太多,有可能让新手蒙圈,现在AI非常给力,可以直接让AI解释每个数据项的含义。
有了atop,你就不用担心“坏了,我没及时登机器,现场丢了”。
进一步分析排查
上述工具,并不是排查问题、解决问题的全部,是排查问题时的前60s的排查建议,我觉得这个checklist还是比较中肯的。
当我们确定了问题大约在哪个范围之后,你就可以继续深入排查,以go开发为例:
- 比如是内存使用问题,就可以通过go tool pprof进行内存相关的采样、go tool trace查看内存GC MMU信息,进一步确定内存高占用的原因;
- 比如是cpu使用问题,就可以通过go tool pprof进行cpu采样,查看下热点代码路径;
- 如果是sys占用高问题,也可以查看是不是存在大量的syscall之类的;
- 如果是网络、磁盘IO、kernel……
当我们缩小问题范围后,就需要借助合适的工具进一步排查,这个过程可能是层层深入的过程,甚至于没有现成的工具供你使用。换言之,大佬们给我们传递的始终是方法学、解决问题的模式,具体到不同的问题本身还是要case by case的分析。
有可能大佬们沉淀了一些工具给我们使用,比如本书《BPF Performance Tools》中介绍的BCC包中的大量基于ebpf的分析工具。但是仍然有可能你需要自己开发工具,现在基于ebpf你可以做的、探查的更深入、更多。
本文总结
本文介绍了Gregg《BPF Performance Tools》中提及的Netflix工程团队Linux性能问题排查60s checklist,介绍了下其checklist中提及的工具及适用范围,也介绍了下作者本人工作期间常用的Linux时光机atop,最后引出了ebpf这个当前在可观测性领域大火的技术。
后面有机会的话,也会就ebpf在可观测性领域的应用、开发实践进行介绍 😃