观测Go函数调用:go-ftrace 设计实现
Posted 2023-12-12 12:42 +0800 by ZhangJie ‐ 11 min read
前言
不久前在团队内部做了点eBPF相关的技术分享,过程中介绍了下eBPF的诞生以及在安全、高性能网络、可观测性、tracing&profiling等领域的实践以及巨大潜力。另外,在我们项目开发测试过程中,也希望对go程序的性能有更好的把控,所以对“上帝视角”的追求是会上瘾的,所以我们也探索了下如何基于eBPF技术对go程序进行无侵入式地观测。
分享过程中也演示了下我现阶段开发的go函数调用可观测性工具。下面是我的分享PPT,感兴趣的话可以打开阅读:eBPF原理及应用分享,欢迎一起学习交流。
基础知识
本文重点不在于eBPF扫盲,但是如果有eBPF的基础的话,再看本文对go-ftrace的介绍会事半功倍。所以如果对eBPF没什么了解,可以先看看我的分享PPT,或者其他资料,知道个大概。
go-ftrace主要是对go程序中的函数调用进行跟踪并统计其耗时信息,也可以获取函数调用过程中的参数信息,这样结合起来,你可以看到不同输入下的处理耗时的差异。
我们在前一篇文章里介绍了如何使用go-ftrace来跟踪go程序中的某些函数,甚至获取其执行过程中的函数参数信息。本文来详细介绍下go-ftrace的设计实现。
内核视角
自打1993年bpf(berkeley packet filter)技术出现以来,这种CFG-based(control flow graph)的字节码指令集+虚拟机的方案就取代了当时的Tree-based cspf (cmu/standford packet filter)方案,而后几年在Linux内核中引入了bpf,定位是用来做些tcpdump之类的包过滤分析,在后来Linux内核中引入了kprobe技术,允许用户在内核模块中通过kprobe跟踪内核中的一些函数来进行观测、分析,此后的很多年,bpf技术一直在改进,逐渐演化成一个独立的eBPF子系统,kprobe、uprobe也可以直接回调eBPF程序,使得整个Linux内核变得可编程,而且是安全的。
从跟踪角度来看,有静态跟踪、动态跟踪两种方式,静态跟踪主要是Linux内核中的一些tracepoints,动态跟踪主要是借助kprobe、uprobe技术。如果你阅读过我之前写的调试器的书籍(还未100%完成),你肯定会对“指令patch”技术有所了解,其实kprobe、uprobe技术的工作原理也是借助指令patch。
- 当我们通过系统调用bpf通知内核在指令地址pc处添加一个kprobe或者uprobe时,内核会将对应地址处的指令(有可能是多个字节)用一个一字节指令Int 3 (0xcc)代替,并在内核数据结构中记录下原指令内容,以及这个地址处是否是一个kprobe、uprobe。
- 当内核执行到这个指令0xcc时,它会触发一个异常,进而会执行Linux内核中断服务程序对其进行处理,内核会检查这个地址pc处是否有相关的kprobe、uprobe,有的话就跳过去执行,每个kprobe、uprobe实际上包含了prehandler、原指令、posthandler。先执行prehandler,如果返回码ok则继续执行原指令,再执行posthandler;如果prehandler返回错误码,那就不往后执行了,通过这个办法也可以拦截某些系统调用,如seccomp-bpf技术。
大致就是这样的一个过程,仔细深究的话kprobe、uprobe工作起来稍微有点差异。
- 注册kprobe你只需要告诉内核一个符号即可,比如一个系统调用名,内核会自己计算出这个符号对应的指令地址;
- 而注册一个uprobe的话,举个例子,go main.main函数,内核是不认识这个符号的,它也不知道main.main的地址该如何计算出来,就需要我们自己先算出来它的地址(实际上是相对于ELF文件开头的偏移量),然后再传给内核;
调试知识
那么针对不同的编程语言写的程序,如何指定一个符号来计算出对应的指令地址呢?这就是挑战点之一,不过在调试领域这个问题早就已经解决了,我们可以借鉴下来解决计算指定函数名的指令地址的问题。
DWARF,是一种调试信息标准,目前是使用最广泛的调试信息格式。其实有多种调试信息格式,但是从对不同编程语言、不同特性、数据编解码效率的优势来看,它确实更胜一筹,所以现在主流编程语言生成的调试信息基本都是支持DWARF或者优先考虑DWARF。
以go语言为例,当我们执行go build编译一个可执行程序时,以ELF binary文件为例,编译器、链接器会生成一些.[z]debug_开头的sections,这些sections中的数据就是调试信息。
常见的ELF sections及其存储的内容如下:
.debug_abbrev, 存储.debug_info中使用的缩写信息;
.debug_arranges, 存储一个加速访问的查询表,通过内存地址查询对应编译单元信息;
.debug_frame, 存储调用栈帧信息;
.debug_info, 存储核心DWARF数据,包含了描述变量、代码等的DIEs;
.debug_line, 存储行号表程序 (程序指令由行号表状态机执行,执行后构建出完整的行号表)
.debug_loc, 存储location描述信息;
.debug_macinfo, 存储宏相关描述信息;
.debug_pubnames, 存储一个加速访问的查询表,通过名称查询全局对象和函数;
.debug_pubtypes, 存储一个加速访问的查询表,通过名称查询全局类型;
.debug_ranges, 存储DIEs中引用的address ranges;
.debug_str, 存储.debug_info中引用的字符串表,也是通过偏移量来引用;
.debug_types, 存储描述数据类型相关的DIEs;
以我们的go-ftrace为例,我们想跟踪某个函数的执行,就得先通过函数名找到对应的地址,怎么找呢?就是借助前面提到的这些.debug_ sections。简单说就是我们可以通过这些不同的调试信息构建起对go源码层面的全局视图,并且能在源码和内存表示(包括指令地址)之间建立起一种映射关系。
这样我们就可以知道每个函数的第一条指令地址是多少,然后告诉内核分别在函数进入、退出的位置设置uprobes,然后我们为函数进入、返回这两类uprobes分别编写对应的eBPF回调函数。在进入的时候记录下此时的时间戳,在退出的时候也记录下时间戳,然后就可以计算耗时信息。
尽管不了解DWARF也不妨碍阅读理解本文的大意,但如果想能定制化go-ftrace这样的工具,不了解DWARF是基本不可能做到的。如果你想了解这方面内容,建议阅读DWARF文档,或者阅读我的电子书golang-debugger-book 里关于DWARF的相关章节。目前DWARF v5出来不久,v5的特性使用还没有那么广泛,v4应用最广泛。
设计目标
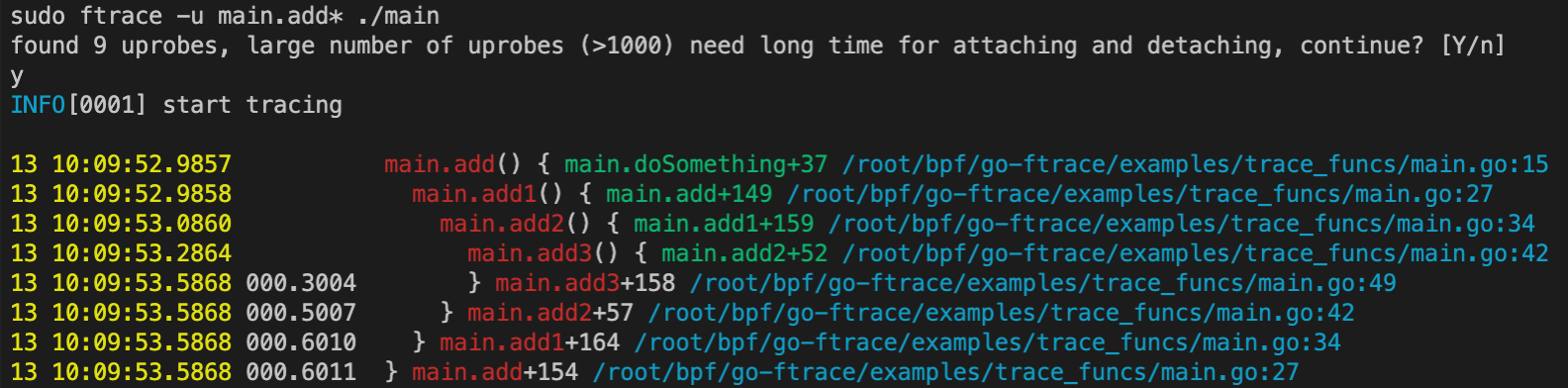
假定存在如下go代码,逻辑很简单,循环doSomething。为了演示trace跟踪时也能跟踪目标函数内部对其他函数的调用,示例代码中添加了add、add1、add2、add3,为了展示对函数执行耗时的统计,在不同函数内部加了sleep来模拟各函数的执行耗时。为了避免内联优化对DWARF分析函数位置的影响,我们在上述函数前面加了//go:noinline。
ps: 随着go编译工具链对内联函数生成的DWARF信息的优化,后续应该也可以去掉内联,现在加上最稳妥。
func main() {
for {
doSomething()
}
}
func doSomething() {
add(1, 2)
...
time.Sleep(time.Second)
}
//go:noinline
func add(a, b int) int {
fmt.Printf("add: %d + %d\n", a, b)
return add1(a, b)
}
//go:noinline
func add1(a, b int) int {
fmt.Printf("add1: %d + %d\n", a, b)
time.Sleep(time.Millisecond * 100)
return add2(a, b)
}
//go:noinline
func add2(a, b int) int {
time.Sleep(time.Millisecond * 200)
return add3(a, b)
}
//go:noinline
func add3(a, b int) int {
fmt.Printf("add3: %d + %d\n", a, b)
time.Sleep(time.Millisecond * 300)
return a + b
}
然后希望执行 ftrace -u main.add* ./main时,函数调用跟踪及耗时统计可以达到这样的效果,能展示函数执行进入、退出的时间戳、耗时,函数调用发生的位置,甚至函数实参信息。
实现过程
下面按照程序执行流程,对流程中涉及到的技术细节进行下详细介绍。
解析启动参数
为了更方便使用POSIX风格的命令行选项参数(长选项、短选项),这里还是使用的spf13/cobra来开发这个程序,原作者用的另外一个库,但是我使用起来感觉不太方便,所以这部分进行了重写,也方便我后续扩展其他功能。
主要参数有这几个:
// 是否排除vendor/定义的函数
rootCmd.Flags().BoolP("exclude-vendor", "x", true, "exclude vendor")
// 指定要跟踪的函数名匹配模式
rootCmd.Flags().StringSliceP("uprobe-wildcards", "u", nil, "wildcards for code to add uprobes")
// 将参数-u设置为必填参数
rootCmd.MarkFlagRequired("uprobe-wildcards")
当我们执行命令时就可以像下面这样使用:
# 跟踪binary中main包下所有的函数、方法,而且可以多次使用-u指定多个匹配模式
ftrace [-u|--uprobe-wildcards] main.* <binary>
# 也可以指定-x来排除vendor下定义的函数、方法
ftrace -u github.com/* [-x|--exclude-vendor] <binary>
# 也可以自定参数来描述如何获取指定函数的参数信息
ftrace -u main.Add <binary> 'main.Add(p1=expr1:type1, p2=expr2:type2)'
spf13/cobra是一个很好用的命令行工具开发框架,感兴趣的可以了解不再赘述。大致知道为什么我们选择它就可以:支持POSIX风格选项解析(长选项、短选项)、方便扩展命令、选项、自动生成help信息、自动生成shell补全脚本。
匹配函数获取
以我们指定的main.*这个匹配表达式为例,我们如何找到所有匹配的函数名呢?我们是拿不到源代码信息的,我们能拿到的只有已经编译构件号的go二进制程序。其实编译器、链接器已经生成了一些.symtab, .strtab,我们的函数名就存在于这些section中,并且对于一个Symbol,除了名字,还记录了这个符号表示的对象类型,比如“函数”。
看下下面的示例代码:获取所有函数命名形如 main.*的函数。
// 首先打开一个elf文件,其中的.symtab, .strtab没有被stripped
f, err := elf.Open("testdata/helloworld")
// 取出所有的symbols
syms, err := f.Symbols()
var funcs []string
for _, s := range syms {
// 如果不是函数类型跳过
if elf.ST_TYPE(s.Info) == elf.STT_FUNC {
continue
}
// 如果命名不匹配main.*跳过
if !strings.Contains(s.Name, "main.") {
continue
}
// 记录下函数名
funcs.append(funcs, s.Name)
}
在go-ftrace里面,为了实现方便组合使用了go-delve/delve下的DWARF相关package,以及标准库debug/elf,原理和上面是一致的。这样下来我们就获得了所有匹配模式main.*的待跟踪函数列表。
函数地址转换
有了这些带跟踪的函数名列表之后,我们希望程序执行时进入、退出函数时能生成一个事件并回调自定义的回调函数,回调函数里我们分别统计开始执行时间、介绍执行时间,这样就能计算出这个函数的耗时信息。
要想在函数进入、退出时产生回调特定函数,就要利用到eBPF+uprobe了,我们用eBPF写uprobe的回调函数,再通过bpf系统调用通知内核将某个uprobe和eBPF程序attach起来之前,我们得先创建uprobe。在创建uprobe之前,我们得先知道每个待跟踪函数的入口指令的地址,以及返回指令的地址,这里的地址后面用pc(程序计数器)代替。
ps: 学过组成原理的话,应该了解到pc=cs:ip,其实就是下条待执行指令的地址,但是我们这里用pc代指了函数入口指令地址、返回指令地址。
函数入口添加uprobe
获得函数入口指令地址,也并不困难,下面是获取入口指令地址、offset(相对于ELF文件开始位置)的示例代码:
sym, err := elf.ResolveSymbol(funcname)
if err != nil {
return nil, err
}
// 函数入口偏移量
entOffset, err := elf.FuncOffset(funcname)
if err != nil {
return nil, err
}
uprobes = append(uprobes, Uprobe{
Funcname: funcname,
Location: AtEntry,
Address: sym.Value, // 指令地址
AbsOffset: entOffset, // 相对偏移量
RelOffset: 0, // 相对入口指令偏移量,当然是0
})
那elf.FuncOffset(funcname)是如何实现的呢?
// 返回函数定义在ELF文件中的偏移量
func (e *ELF) FuncOffset(name string) (offset uint64, err error) {
sym, err := e.ResolveSymbol(name)
if err != nil {
return
}
section := e.Section(".text")
return sym.Value - section.Addr + section.Offset, nil
}
有几个地方要说明下:
- symbol.Value:符号表示的对象(变量、类型、函数等)在进程虚地址空间中的地址;
- section.Addr:如果不为0表示会被加载到内存,它表示该section第一字节在进程虚地址空间中的地址;
- section.Offset:表示该section第一字节在ELF文件中的偏移量;
所以 sym.Value - section.Addr + section.Offset表示该符号在ELF文件中的偏移量。这可能和我们预期的“虚拟内存地址pc”有点偏差。或者说,当执行系统bpf系统调用设置uprobe时,我们实际传入的位置信息:
- 是一个相对于ELF文件开头的偏移量呢?
- 还是一个相对于.text section开头的偏移量呢?
- 还是一个虚拟内存地址呢?
go-ftrace执行bpf操作是利用了cilium/bpf工程提供的封装,``github.com/cilium/ebpf/link.Uprobe|Uretprobe(),这几个函数也是允许指定symbol,那前面获取这些符号地址有啥作用呢?是这样的,Uprobe、Uretprobe只能处理非共享库、且语言是CC++之类的场景,如果是共享库或者是其他语言的,需通过UprobeOptions{Offset: …}`来说明uprobe位置(ELF文件中指令相对于文件开头的偏移量)。
所以你看我前面计算了很多AbsOffset偏移量(相对于ELF文件开头),最终就是利用这些偏移量来设置的。如果进一步了解下cilium使用的系统调用perf_event_open,会了解的更清楚。perf_event_open,该系统调用允许接受一个perf_event_attr的参数来设置kprobe、uprobe。
$ man 2 perf_event_open
…
kprobe_func, uprobe_path, kprobe_addr, and probe_offset
These fields describe the kprobe/uprobe for dynamic PMUs kprobe and uprobe.
- For kprobe: use kprobe_func and probe_offset, or use kprobe_addr and leave kprobe_func as NULL.
- For uprobe: use uprobe_path and probe_offset.
再看cilium中对此系统调用的使用过程,看下它是怎么设置perf_event_attr参数的:
func pmuProbe(typ probeType, args probeArgs) (*perfEvent, error) {
...
var (
attr unix.PerfEventAttr
sp unsafe.Pointer
)
switch typ {
case kprobeType:
...
case uprobeType:
sp, err = unsafeStringPtr(args.path)
if err != nil {
return nil, err
}
...
attr = unix.PerfEventAttr{
Size: unix.PERF_ATTR_SIZE_VER1,
Type: uint32(et), // PMU event type read from sysfs
Ext1: uint64(uintptr(sp)), // Uprobe path(二进制文件)
Ext2: args.offset, // Uprobe offset (相对于ELF文件)
...
}
}
rawFd, err := unix.PerfEventOpen(&attr, args.pid, 0, -1, unix.PERF_FLAG_FD_CLOEXEC)
...
}
通过man perf_event_open查看attr结构体定义,实际上上述代码中Ext1、Ext2分别对应uprobe_path和probe_offset,刚好对上。uprobe_path实际上就是我们的二进制程序的路径信息,而probe_offset就是要设置uprobe的指令处在ELF文件中的偏移量信息。
之后,内核会读取并解析uprobe_path对应ELF文件的headers信息,计算probe_offset处指令对应的uprobe地址,然后注册uprobe。
ps:不禁要问,内核为什么不直接要一个逻辑地址来描述uprobe的位置呢?考虑下来可能就是为了一致性、简单性、可理解性。用逻辑地址可以吗?实现肯定能实现,但是看到这种参数开发者要去理解地址映射逻辑、加载逻辑,至少会去“仔细”确认这些信息吧。内核中其他系统调用在处理类似场景时可能也是更倾向于使用offset,应该也有一致性的考虑。先知道这个就行了。
函数返回前添加uprobe
函数返回时比较特殊,它可能存在多个返回语句,这个也比较好理解。多个返回语句,也就是多条返回指令,每个返回指令地址处都应该添加uprobe。
// 函数返回指令偏移量
retOffsets, err := elf.FuncRetOffsets(funcname)
for _, retOffset := range retOffsets {
uprobes = append(uprobes, Uprobe{
Funcname: funcname,
Location: AtRet,
//Address:
AbsOffset: retOffset, // 返回指令的偏移量(相对于ELF文件)
RelOffset: retOffset - entOffset, // 返回指令的偏移量(相对函数入口)
})
}
// FuncRetOffsets returns the offsets of RET instructions of function `name` in ELF file
//
// Note: there may be multiple RET instructions in a function, so we return a slice of offsets
func (e *ELF) FuncRetOffsets(name string) (offsets []uint64, err error) {
insts, _, offset, err := e.FuncInstructions(name)
if err != nil {
return
}
for _, inst := range insts {
if inst.Op == x86asm.RET {
offsets = append(offsets, offset)
}
offset += uint64(inst.Len)
}
return
}
注意到,在设置函数入口的uprobe时,我们是设置了Uprobe.Address字段的,但是设置函数退出的uprobe时却没有,为什么呢?
- 在注册uprobe时,确实只需要指令地址相对于ELF文件的偏移量(前面已解释过);
- 在设置函数入口Uprobe.Address,主要是为了用来设置eBPF maps中的配置信息,如我们跟踪的某个函数是否需要获取参数之类的,而这之需要设置函数入口处的uprobe就够了,函数返回处的uprobe就不需要再计算并设置其地址信息了。
DWARF中函数的lowpc、highpc的指令地址,这个地址是指令的逻辑地址,上述实现FuncRetOffset(name string)中做了从逻辑地址向ELF文件开头的偏移量的转换。
ps:函数的lowpc实际上是函数被编译后第一条指令的逻辑地址,highpc是最后一条指令的逻辑地址。函数定义在DWARF中是以DIE(Debugging Information Entry)的形式存储在.[z]debug_info中的,对于描述函数的DIE,其Tag会表明它是一个TagSubprogram(函数),同时它会包含相关的AttrLowpc、AttrHighpc来描述函数包含的指令集合的逻辑地址范围。了解这写些就可以了,不再继续展开。
参数寻址规则
如果我们需要获取函数的参数信息,该怎么办?很简单,其实只要知道参数在内存中的起始地址,以及数据类型信息就可以了。这样我们就可以按照指定的数据类型的大小从内存读取一定数量的bytes,然后再将其解析成对应的数据类型即可。
ps:当然这里的参数也可能是一个寄存器中的立即数,这样就简单了很多。
这里的寻址规则,我们可以自己设计一个,比如借鉴下计算机组成原理的有效地址(EA,Effective Address)的寻址方式的写法,这里我们为了实现起来简单,又便于理解,自己设计了一种写法。
// 基本写法
functionName(argument1=(expr1):type1, argument2=(expr2):type2, argument3=(expr3):type3)
- argument1~3: 这是我们为要捕获的参数自定义的一个标识符名
- expr1~3: 这是参数值实际存储的有效地址,必须先从有效地址处读取数据,然后才能解析成期望类型(也可能是一个寄存器立即数)
- type1~3: 这是参数值对应的数据类型,’s|u' for 整数, ‘c’ for 字符串
- s64 表示64位 有符号整数
- u64 表示64位 无符号整数
- c64 表示共8字节的字符串
以这个为例,我们解释下它的含义:
main.(*Student).String(s.name=(*+0(%ax)):c64, s.name.len=(+8(%ax)):s64, s.age=(+16(%ax)):s64)
其中main.(*Student).String()的定义如下:
// go代码Student定义
type Student {
name string
age int
}
实际上pahole分析出的它的内存布局:
$ ../scripts/offsets.py --bin ./main --expr 'main.Student'
struct main.Student {
struct string name; /* 0 16 */
int age; /* 16 8 */
/* size: 24, cachelines: 1, members: 2 */
/* last cacheline: 24 bytes */
};
对于String()方法,其第一个参数是其接收器类型main.(*Student),它的起始地址将通过AX寄存器传递,在规则中我们使用%ax代表物理寄存器RAX or EAX,然后呢Student.age相对于Student对象起始的偏移量是16字节,所以规则 s.age=(+16(%ax)):s64指出了age的有效地址+16(%ax),以及数据类型s64。规则中的()只起到分组、增强可读性的作用,并不像计算机组成原理中那样用来取数据(取寄存器或者内存单元中的数据)。
类似地,对Student.name我们也可以这样分析,只不过对于string类型比较特殊:
$ ../scripts/offsets.py --bin ./main --expr 'main.Student->name'
Member(name='name', type='string', is_pointer=False, offset=0)
struct string {
uint8 *str; /* 0 8 */
int len; /* 8 8 */
/* size: 16, cachelines: 1, members: 2 */
/* last cacheline: 16 bytes */
};
string本身就是一个struct来表述的,它底层数组的起始地址,以及长度信息。其实main.Student的起始地址就是main.Student.name.str成员的起始地址,但是这里的str是一个指针,可以理解成它指向一个长度为len的byte数组。main.Student.name.str成员的起始地址并不是EA,*(main.Student.name.str)才是EA,所以规则里s.name=(*+0(%ax)):c64读者应该看懂了吧。获取name字符串长度的操作s.name.len=(+8(%ax)):s64也不难明白了。
ps:有时候传参是通过寄存器传递的立即数,这种规则就更简单了,比如your_arg=(%si):u64。这里些的比较简短,如果你想详细了解,可以阅读这里的FetchArgRule 获取参数的规则。
协程执行过程
OK,读到这里的都是技术细节控 :) 现在我们知道怎么在函数入口、退出时设置uprobe了,也知道怎么通过寻址规则来获取任意参数的信息了。我们先把任务做的简单点,假设我们只统计函数耗时信息,我们应该怎么做呢?
func main() {
add()
}
func add() {
add1()
}
上述函数在执行时,我们希望统计成这样:
timestamp1 main.main { args...
timestamp2 main.add { args...
timestamp3 main.add1 args...
timestamp4 timecost1 } main.add1 end
timestamp5 timecost2 } main.add end
timestamp6 timecost3 } main.main end
要知道,main.add、main.add1 函数可能在任意goroutine中被调用,那么我们汇总上述函数调用过程中的耗时时就必须意识到,我们要针对每个goroutine单独统计它执行过程中的函数栈帧的expand、shrink问题:
- 函数调用进入,新建一个栈帧
- 函数调用返回、栈帧销毁
比如我们分析一个函数main.main,我们就会将main.main这个位置作为一个根,在其下发起的新的函数调用、返回都伴随着在根下新建节点、移除节点的过程,当每个节点新建、移除时我们就收集到了一连串的事件(uprobe、uretprobe事件被触发,对应的时间戳被记录下来),然后最后连根main.main也返回时,就意味着我们观测的对象已经执行结束了,我们已经收集全了所有的信息,现在是时候打印出上述收集到的执行信息了。
所以,其实我们可以用一个栈(stack)来记录每个goroutine上的信息函数调用、函数返回的事件信息,当栈空时就可以打印收集到的执行信息,并清空这些信息。后续goroutine仍然有可能再次执行这个函数,这个栈又会增长、缩减、被打印执行信息,直到这个goroutine退出时,我们就可以从eBPF maps中删除这个goroutine对应的栈数据结构。
大致实现过程就是这样的,那很重要的一点就是,我们必须获取到goroutine的唯一标志goid,这样我们才能在eBPF maps中为每个goroutine创建与之关联的stack。
获取协程goid
先说事实,goid是存储在runtime.g这个结构体中的成员,而runtime.g的地址是存储在线程局部存储(Thread Local Storage,TLS)中的。
那么,如果我们知道TLS在虚拟内存空间中的存储位置,并且知道runtime.g在TLS block中的偏移量信息,那么我们就能读取出runtime.g的地址。如果我们再知道goid相对于包含它的结构体runtime.g的offset,那么我们也就可以继续读取出goid的值。
如何获取TLS地址
TLS地址在现代处理器中一般是有专门的寄存器来存的,比如FS寄存器。以Linux为例,这个寄存器的数据会存储在task_struct->thread (thread_struct) -> fsbase字段中:
- 获取指定任务task_struct在eBPF程序中是很简单的事情,仅需要调用函数
bpf_get_current_task即可; - 然后通过offsetof,我们可以轻易获取到thread成员相对于task_struct的偏移量,这里的thread_task是个结构体;
- 然后继续获取fsbase相对于thread_task的偏移量,这样就可以获取出fsbase的值;
简言之最终的fsbase相对于task_struct的偏移量就是这样:
// offset of `task_struct->thread_struct->fsbase`, `fsbase` contains the TLS
// offset. On Linux register `FS` is used to load the TLS base address.
#define fsbase_off (offsetof(struct task_struct, thread) + offsetof(struct thread_struct, fsbase))
然后这样就可以读取到TLS的地址了:
__u64 tls_base, g_addr, goid;
struct task_struct *task = (struct task_struct *)bpf_get_current_task();
bpf_probe_read_kernel(&tls_base, sizeof(tls_base), (void *)task + fsbase_off);
如何获取runtime.g在TLS中偏移量
要想准确获取runtime.g在TLS block中的offset,还是有一点复杂的,因为这里牵扯到了不同链接方式、不同平台的差异性,对于纯go程序而言就比较简单,runtime.g相对于TLS块的偏移量是-8。
ps:您可以阅读下面代码了解下在非纯go等情景下,偏移量是如何计算的。
// FindGOffset returns the runtime.g offset
//
// see: github.com/go-delve/delve/proc/bininfo.go:setGStructOffsetElf,
//
// it summarizes how to get the runtime.g offset:
// This is a bit arcane. Essentially:
// - If the program is pure Go, it can do whatever it wants, and puts the G
// pointer at %fs-8 on 64 bit.
// - %Gs is the index of private storage in GDT on 32 bit, and puts the G
// pointer at -4(tls).
// - Otherwise, Go asks the external linker to place the G pointer by
// emitting runtime.tlsg, a TLS symbol, which is relocated to the chosen
// offset in libc's TLS block.
// - On ARM64 (but really, any architecture other than i386 and x86_64) the
// offset is calculated using runtime.tls_g and the formula is different.
//
// well, this is a bit hard to master all this kind of history.
// but, we can show respect to the contributors.
func (e *ELF) FindGOffset() (offset int64, err error) {
_, symnames, err := e.Symbols()
if err != nil {
return
}
// When external linking, runtime.tlsg stores offsets of TLS base address
// to the thread base address.
tlsg, ok := symnames["runtime.tlsg"]
tls := e.Prog(elf.PT_TLS)
if ok && tls != nil {
// runtime.tlsg is a symbol, its symbol.Value is the offset to the
// beginning of the that TLS block.
//
// FS register is the offsets which points to the end of the TLS block,
// this block's size is memsz long.
//
// so, offsets where runtime.g stored = FS + runtime.tlsg.Value - memsz
memsz := tls.Memsz + (-tls.Vaddr-tls.Memsz)&(tls.Align-1)
return int64(^(memsz) + 1 + tlsg.Value), nil
}
// While inner linking, it's a fixed value -8 ... at least on x86+linux.
return -8, nil
}
这样,我们就可以进一步读取到runtime.g的地址信息:
bpf_probe_read_user(&g_addr, sizeof(g_addr), (void *)(tls_base + CONFIG.g_offset));
获取goid的偏移量
因为runtime.g的源码是公开的,要确定goid的偏移量的话,易如反掌,也可以通过前面介绍的pahole工具自动分析下。假定这个偏移量是goid_offset的话。
最终我们就可以读取出goid的值:
bpf_probe_read_user(&goid, sizeof(goid), (void *)(g_addr + CONFIG.goid_offset));
有了goid之后,我们就可以用它做eBPF maps中的goroutine的key,来记录每个协程关联的一些事件统计数据。
加载BPF程序
前面讲了如何获取函数定义入口的指令地址、返回指令的指令地址相对ELF文件的偏移量问题。并且也提到了Linux系统调用perf_event_open的参数perf_event_attr如何来设置uprobe的位置信息(uprobe需要通过uprobe_path、probe_offset)。但是在注册uprobe时,我们不光要指定待跟踪的位置信息,还需要指定当程序执行到这个位置时,应该如何反应。所以在本小节之后我们还要描述下自定义的uprobe的回调函数的内容,也就是我们eBPF程序。
这里我们先不管eBPF程序怎么写,先描述下eBPF程序的加载,加载过程归根究底是利用了系统调用bpf(2)来完成,此时只是提交给内核一个eBPF程序,该程序已经通过clang -target=bpf编译成了bpf字节码指令,提交给内核后eBPF子系统中的验证器开始工作,它会检查该eBPF程序是否符合要求,比如是否很复杂、是否有无穷或者次数很多的循环、是否有内存越界等行为,只有符合要求的程序才会通过验证并加载。eBPF子系统还会调用JIT编译期将bpf字节码指令进一步转换为native指令,使其执行效率接近原生指令效率。
接下来,我们就看下go-ftrace里面是如何加载eBPF程序的,它没有直接调用bpf系统调用,而是使用了cilium/bpf中对该系统调用的封装。
// load bpf programme and setup bpf programme config
if err = t.bpf.Load(uprobes, bpf.LoadOptions{
GoidOffset: goidOffset,
GOffset: gOffset,
}); err != nil {
return
}
这个过程中具体做了哪些事情呢?
// Load 加载这个bpf程序
func (b *BPF) Load(uprobes []uprobe.Uprobe, opts LoadOptions) (err error) {
// 加载bpf程序,这部分是用C语言写的,然后clang编译成-target bpf的字节码程序,扩展名为*.o,
// 这个*.o文件也是ELF文件头的
spec, err := LoadGoftrace()
if err != nil {
return err
}
b.objs = &GoftraceObjects{}
...
// 是否要获取参数:遍历所有uprobes,检查有没有要获取参数的,有就更新为true
fetchArgs := false
// 返回一个bpf配置,并将cfg写入eBPF maps,作为运行在内核态的bpf程序要读取的配置
cfg := b.BpfConfig(fetchArgs, opts.GoidOffset, opts.GOffset)
if err = spec.RewriteConstants(map[string]interface{}{"CONFIG": cfg}); err != nil {
return
}
// 继续加载*.o中的bpf程序和maps
if err = spec.LoadAndAssign(b.objs, &ebpf.CollectionOptions{
Programs: ebpf.ProgramOptions{LogSize: ebpf.DefaultVerifierLogSize * 4},
}); err != nil {
return
}
// 遍历所有uprobes中的参数获取规则,将其写入bpf maps配置arg_rules_map中,
// - key就是函数入口地址,
// - val就是该函数的多个参数获取的规则描述配置
for _, uprobe := range uprobes {
if len(uprobe.FetchArgs) > 0 {
if err = b.setArgRules(uprobe.Address, uprobe.FetchArgs); err != nil {
return
}
}
...
}
return
}
主要是这里的LoadAndAssign函数,我们用C写的bpf程序部分是运行在内核态中的,它被clang编译为-target bpf的字节码程序,在C程序中通过一些特定的编译器扩展允许指定编译器、链接器将特定的函数编译后写入特定的ELF section中。
SEC("uprobe/ent")
int ent(struct pt_regs *ctx)
{
__u32 key = 0;
struct event *e = bpf_map_lookup_elem(&event_stack, &key);
if (!e)
return 0;
__builtin_memset(e, 0, sizeof(*e));
...
}
SEC("uprobe/ret")
int ret(struct pt_regs *ctx)
{
__u32 key = 0;
struct event *e = bpf_map_lookup_elem(&event_stack, &key);
if (!e)
return 0;
__builtin_memset(e, 0, sizeof(*e));
...
}
#define SEC(name) \
_Pragma("GCC diagnostic push") \
_Pragma("GCC diagnostic ignored \"-Wignored-attributes\"") \
__attribute__((section(name), used)) \
_Pragma("GCC diagnostic pop")
比如上面的程序在被clang -target bpf编译为*.o文件后,尝试用readelf读取sections定义:
$ readelf -S goftrace_bpfel_x86.o
There are 31 section headers, starting at offset 0xc0a90:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
...
[ 3] uprobe/ent PROGBITS 0000000000000000 00000040
0000000000000c48 0000000000000000 AX 0 0 8
[ 5] uprobe/ret PROGBITS 0000000000000000 00000c88
0000000000000200 0000000000000000 AX 0 0 8
...
Load过程中就会遍历并记录下上述特殊的sections的内容,每一个section的内容都是一个*ebpf.Program,也就是SEC(name)这里的name函数期望的eBPF回调程序。
ps:除了加载这些bpf程序到内核,它也会加载定义的一些bpf maps数据结构,如用到的hash、queue、stack、array,这些数据结构可能会用来充当配置,也可能用来存储执行结果,实现用户态、内核态的数据交互。这些maps数据结构定义,编译后会统一放在maps这个ELF section中。
以函数参数的获取规则为例,arg_rules_map 是一个hash,kv存储结构,k就是函数入口地址,v就是对一个函数的参数获取规则。arg_rules_map通过SEC(“maps”)来修饰,编译后会记录在ELF maps section中,这里的加载逻辑就是告诉内核给创建一个这样的结构备用。然后通过b.setArgRules(uprobe.Address, uprobe.FetchArgs)来填充数据。
struct bpf_map_def SEC("maps") arg_rules_map = {
.type = BPF_MAP_TYPE_HASH,
.key_size = sizeof(__u64),
.value_size = sizeof(struct arg_rules),
.max_entries = 100,
};
关联BPF程序
attach eBPF程序,这里翻译为了“关联”,可能不太贴切……关联的过程就简单了,只需要通过系统调用来将函数入口地址、返回地址,与对应的eBPF程序关联起来即可。
up, err := ex.Uprobe("", prog, &link.UprobeOptions{Offset: up.AbsOffset})
if err != nil {
return err
}
其中prog就是section中的回调程序,然后后面的link.UprobeOptions.Offset就是函数入口地址相对ELF文件开头的偏移量,这几个参数传给系统调用,就可以完成uprobe和eBPF程序的关联。
生成事件信息
还记得这张图吗,我们前面讲的都是ftrace工具的用户态部分,包括如何确定要跟踪的函数、确定函数进入退出的uprobes、将内核态部分加载到内核,并将uprobes与bpf程序关联起来。
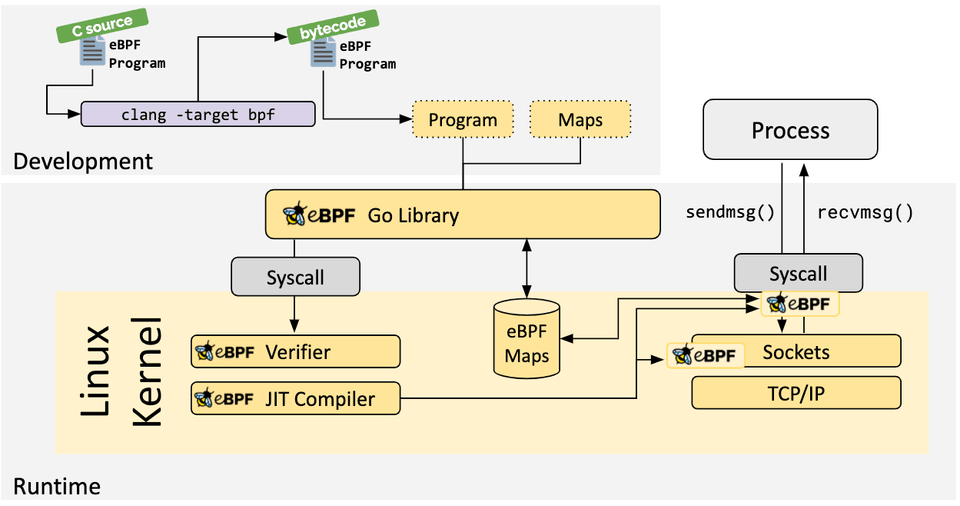
我们还没有讲内核态部分的逻辑是怎么实现的?接下来我们就需要看看每个回调函数是如何写的,它们怎么记录事件的,然后用户态程序部分怎么轮询事件的。
截止到目前为止,大部分的eBPF程序内核态部分都是通过C语言来写的,当然Rust可以使用Aya来写,其他语言只能用C写完内核态部分后再使用编译器编译为eBPF字节码,然后通过系统调用load、attach。我们这里也是使用C语言来写。
这部分的设计实现,参考了go调试器go-delve/delve中的设计实现,为什么调试器也会用到eBPF呢?因为调试器中也有tracepoint之类的设计,当执行到某个地方时打印一下,eBPF就很合适。部分代码也是摘取自go-delve/delve,言归正传说下这里的实现。
函数入口事件
当一个函数调用发生时,首先触发的是uprobe/ent,对应的函数定义如下,这个函数最终编译后会存储在ELF文件的section uprobe/ent中,然后Load、Attach的时候将uprobe的ip和这段prog attach起来。等函数调用发生时,就会回调这里的函数。
看下这个函数的逻辑,大致逻辑就是,生成一个新的事件event,其中记录下来goid、ip、类型、时间戳,这样就能描述谁(goid)在什么时间(time_ns)调用(ENTRY)了什么函数(ip)。bp、caller bp、caller ip可以帮助我们进一步确定一些其他信息,后面再解释。
SEC("uprobe/ent")
int ent(struct pt_regs *ctx)
{
// event_stack是一个BPF_MAP_TYPE_PERCPU_ARRAY,每个CPU都有一个独立的数组来记录其事件信息,
// event_stack用来传递每个CPU上的事件信息,这里的key==0,因为event_stack是一个栈,对于任意
// key对应的元素总是存在,这意味着它会创建一个新的event。
__u32 key = 0;
struct event *e = bpf_map_lookup_elem(&event_stack, &key);
if (!e)
return 0;
__builtin_memset(e, 0, sizeof(*e));
// 获取当前cpu上的线程正在执行的协程的goid,并将该goid与事件e关联起来,表示事件e是由goid标识
// 的协程触发的,同时也将当前的ip(函数入口地址)与事件e关联起来。
// ... 这里可能有点好奇,这里的事件e到底是个什么东西?
e->goid = get_goid();
e->ip = ctx->ip;
// ip表示触发uprobe对应的函数入口地址,这里通过hash结构should_trace_rip查询该函数是否应该被
// 跟踪,这个hash的写入是在bpf.(*BPF).Load(urpobes, opts)方法中设置的,根据uprobe来设置某
// 个rip是否应该被跟踪 ... 这一步疑似有些多余,因为不跟踪压根不会走到这里
//
// 如果当前函数不该被跟踪,并且当前goid也没有过记录,就返回
if (!bpf_map_lookup_elem(&should_trace_rip, &e->ip))
{
if (!bpf_map_lookup_elem(&should_trace_goid, &e->goid))
return 0;
}
// 如果当前函数要被跟踪,但是当前goid没被跟踪过,则应该追踪它
else if (!bpf_map_lookup_elem(&should_trace_goid, &e->goid))
{
__u64 should_trace = true;
bpf_map_update_elem(&should_trace_goid, &e->goid, &should_trace, BPF_ANY);
}
// 记录下当前事件的信息:是进入函数类型、进入事件戳ns、栈基址、调用方栈基址
e->location = ENTPOINT;
e->time_ns = bpf_ktime_get_ns();
e->bp = ctx->sp - 8;
e->caller_bp = ctx->bp;
// 记录发起当前函数调用位置的ip,此时sp指向的位置是caller的返回地址(不了解可以看下函数调用过程
// 中的栈增长过程,压参数、压返回地址、压caller bp、减小rsp分配栈空间)
// see: https://hitzhangjie.gitbook.io/libmill/basics/stack-memory
void *ra;
ra = (void *)ctx->sp;
bpf_probe_read_user(&e->caller_ip, sizeof(e->caller_ip), ra);
// 按需获取参数信息
if (!CONFIG.fetch_args)
goto cont;
fetch_args(ctx, e->goid, e->ip);
cont:
// 将上述事件放到栈 event_queue 中,BPF_EXIST表示如果栈慢了则移除最老的元素腾空间
return bpf_map_push_elem(&event_queue, e, BPF_EXIST);
}
函数返回事件
与函数调用进入相对应的就是函数返回事件,其对应的eBPF处理程序如下:
SEC("uprobe/ret")
int ret(struct pt_regs *ctx)
{
// 生成1个新的事件,用来记录当前函数退出的信息
__u32 key = 0;
struct event *e = bpf_map_lookup_elem(&event_stack, &key);
if (!e)
return 0;
__builtin_memset(e, 0, sizeof(*e));
// 记录执行该函数的goid
e->goid = get_goid();
if (!bpf_map_lookup_elem(&should_trace_goid, &e->goid))
return 0;
// 记录:事件类型(函数退出)、当前ret指令的指令地址、此时的时间戳ns
e->location = RETPOINT;
e->ip = ctx->ip;
e->time_ns = bpf_ktime_get_ns();
// 将当前事件记录到栈中,如果栈满则移除最旧的元素腾空间
return bpf_map_push_elem(&event_queue, e, BPF_EXIST);
}
协程退出事件
当1个协程退出时,就从是否应该跟踪的配置should_trace_goid里删除当前goid,goroutine有自己的生命周期,要及时清理资源,内核对bpf程序要求很苛刻。
SEC("uprobe/goroutine_exit")
int goroutine_exit(struct pt_regs *ctx)
{
__u64 goid = get_goid();
bpf_map_delete_elem(&should_trace_goid, &goid);
return 0;
}
如果一个goroutine退出了,意味着其过去记录的所有函数调用都正常返回了,events栈也是空的,没啥要特殊处理的,这里仅需要从map里删掉这个goid对应的key、value即可,节省空间。
其他考虑
为什么uprobe/ent会有这么奇葩的判断呢?如果当前函数没被跟踪,为什么不直接返回呢?却去判断当前goid应不应该被追踪?可能会有这种极端情况,当我们准备取消跟踪时,此时会更新map里的配置告诉我们的eBPF程序这些函数不要继续追踪了。
那么这里的判断就有意义,它可以避免之前某个goroutine上记录的函数调用链不完整的问题。
if (!bpf_map_lookup_elem(&should_trace_rip, &e->ip))
{
if (!bpf_map_lookup_elem(&should_trace_goid, &e->goid))
return 0;
}
如何获取参数
前面描述了如何描述一个参数的寻址规则,根据具体的EA(Effective Address)或者寄存器中的立即数去读取对应的数据并解析成对应数据类型的工作,其实也是在这个内核态部分去完成的,主要就是靠这两个函数调用:
bpf_probe_read_kernel,读取寄存器信息
bpf_probe_read_user,读取内存信息
如果你对调试器中读取进程内存信息有过了解的话,一定对syscall ptrace的类似操作(PTRACE_PEEK_DATA/PTRACE_POKE_DATA)不陌生,那么理解这里的操作就很容易。无非就是内核提供的工具函数,帮助读取进程上下文中的特定寄存器的值,读取进程地址空间中特定内存位置的信息,仅此而已。
其他的就是对上述寻址规则的利用,我们的有效地址最终会被拆解为一系列的操作:寄存器操作、内存操作1、内存操作2、……,每一步操作都是通过上面的两个工具函数之一来完成,最终读取到想要的参数。
详细实现如下,读取到的函数参数信息,将被记录到对应的参数队列中,等着后续打印过程中去读取、展示。
// 从寄存器中读取参数信息
static __always_inline void fetch_args_from_reg(struct pt_regs *ctx, struct arg_data *data, struct arg_rule *rule)
{
read_reg(ctx, rule->reg, (__u64 *)&data->data);
bpf_map_push_elem(&arg_queue, data, BPF_EXIST);
return;
}
// 从内存中读取参数信息
static __always_inline void fetch_args_from_memory(struct pt_regs *ctx, struct arg_data *data, struct arg_rule *rule)
{
// first read the address from register (well, it maybe a immediate value)
__u64 addr = 0;
read_reg(ctx, rule->reg, &addr);
// then do other addressing rules
for (int i = 0; i < 8 && i < rule->length; i++)
{
// if expr = *+8(+2(%eax)), for *+8 part, we need to dereference the address
if (rule->dereference[i] == 1)
{
bpf_probe_read_user(&addr, sizeof(addr), (void *)addr + rule->offsets[i]);
}
// if the rule is +2 part, then we just add the offset to the address
else
{
addr += rule->offsets[i];
}
}
// finally, we got the EA (effective address), then read the data from it,
// make sure the data size is not larger than MAX_DATA_SIZE
bpf_probe_read_user(&data->data,
rule->size < MAX_DATA_SIZE ? rule->size : MAX_DATA_SIZE,
(void *)addr);
// put the read data into the queue
bpf_map_push_elem(&arg_queue, data, BPF_EXIST);
return;
}
// read register `reg` data from `ctx` into `regval`
static __always_inline void read_reg(struct pt_regs *ctx, __u8 reg, __u64 *regval)
{
switch (reg)
{
case 0:
bpf_probe_read_kernel(regval, sizeof(ctx->ax), &ctx->ax);
break;
case 1:
bpf_probe_read_kernel(regval, sizeof(ctx->dx), &ctx->dx);
break;
...
case 15:
bpf_probe_read_kernel(regval, sizeof(ctx->r15), &ctx->r15);
break;
}
return;
}
轮询事件信息
接下来了解下用户态部分如何读取上面内核态部分记录下来的events信息,这个就很简单了,bpf提供了对应的函数来轮询ebpf maps中的events,读取到之后决定打印还是不打印就可以了。这个地方没有什么特别要注意的,感兴趣可以看下这部分代码。
ctx, stop := signal.NotifyContext(context.Background(), os.Interrupt)
defer stop()
// create eventmanager to poll events, prepare the callstack and print
eventManager, err := eventmanager.New(uprobes, t.drilldown, t.elf, t.bpf.PollArg(ctx))
if err != nil {
return
}
for event := range t.bpf.PollEvents(ctx) {
if err = eventManager.Handle(event); err != nil {
return
}
}
return eventManager.PrintRemaining()
打印函数耗时
怎么将事件信息打印出来,同一个函数可能在多个goroutine中调用,我们记录goroutine上的函数调用、退出时,是每个goroutine(goid唯一标识)单独有一个events stack,需要一个合适的时机将goroutine上的完整events stack打印出来。
当轮询到新事件时,要么是函数调用的进入事件,要么是函数调用的退出事件:
- 如果是函数进入事件,无需特殊处理;
- 如果是函数退出事件,就需要判断下,当前goroutine跟踪到的所有函数级联调用,这个event的到来是不是表示topmost的函数调用已经执行结束了?如果是,那就可以考虑将当前goid对应的events全部打印出来,并清空events stack等着后续收集、打印。
for event := range t.bpf.PollEvents(ctx) {
if err = eventManager.Handle(event); err != nil {
return
}
}
// Handle handles the event
func (m *EventManager) Handle(event bpf.GoftraceEvent) (err error) {
m.Add(event)
log.Debugf("added event: %+v", event)
// CloseStack判断当前event是否是topmost函数调用的返回事件
if m.CloseStack(event) {
// 打印整个调用栈信息,这个就是根据event中记录的信息,打印源码层面的函数名、文件位置、时间戳、耗时信息
if err = m.PrintStack(event.Goid); err != nil {
return err
}
m.ClearStack(event)
}
return
}
// PrintStack print the callstack of a traced function
func (m *EventManager) PrintStack(goid uint64) (err error) {
...
for _, event := range m.goEvents[goid] {
syms, offset, err := m.elf.ResolveAddress(event.Ip)
switch event.Location {
case 0: // entpoint
startTimeStack = append(startTimeStack, event.TimeNs)
callChain, err := m.SprintCallChain(event)
...
if filename, line, err := m.elf.LineInfoForPc(event.CallerIp); err == nil {
lineInfo = fmt.Sprintf("%s:%d", filename, line)
}
fmt.Printf("%s %s %s %s(%s) { %s %s\n",
color.YellowString(t),
placeholder,
indent,
color.RedString(event.uprobe.Funcname),
color.MagentaString(event.argString),
color.GreenString(callChain),
color.CyanString(lineInfo))
case 1: // retpoint
...
if filename, line, err := m.elf.LineInfoForPc(event.Ip); err == nil {
lineInfo = fmt.Sprintf("%s:%d", filename, line)
}
elapsed := event.TimeNs - startTimeStack[len(startTimeStack)-1]
...
}
}
return
}
更好地下钻分析
简单实现
比如main.main->main.add->main.add1,uprobes指定了main.main, main.add, main.add1,假设此时主协程执行main.main->main.add->main.add1,但是另一个协程执行main.add1,这种情况下如果要实现只输出main.main->main.add->main.add1的路径,而忽略掉只执行main.add1的路径,该怎么做呢?
其实可以在打印过程中做文章,如果上面的条件也成立(topmost函数执行结束了),只要额外再判断当前events stack的栈底元素是不是--drilldown funcname指定的函数就可以了,是的话就打印。
一点展望
如果要实现源码层面的更好的下钻分析,离不开对源代码的理解,可行的方案是,借助go build中写入二进制程序中的版本控制信息,去拉取对应的源代码,然后进一步通过AST分析去分析出有哪些函数调用,然后让用户去勾选,勾选上的自动完成对其uprobe的注册、attach,这样就能实现更好地下钻分析。
后续有时间时,将继续在这方面做一点尝试。