上下文切换开销
上下文切换有哪些开销
上下文切换,主要就是任务切换时任务状态的保存,以及选择下一个待执行的任务并将其上下文恢复。这其中的开销,主要包含这么几部分:
切换直接引入的开销
这部分是比较好理解的,保存、恢复上下文时需要保存的寄存器的数据量,直接决定了这部分开销。有些寄存器对上下文切换开销影响是比较大的,比如FPU、MMX、SSE、AVX等寄存器的状态,由于其数据量是比较大的,可能会增加几KB的数据,特别是AVX寄存器,AVX2有512字节,AVX-512有2KB,这么大的数据量在上下文切换时还需要读写内存,这里的内存读写延迟(+读写寄存器)引入的开销是比较大的。
现在也存在“延迟状态加载(lazy state load)”这样的机制,当FPU、MMX、SSE、AVX寄存器没有加载数据时,能够避免加载其中的部分或者全部寄存器数据,从而一定程度上降低开销。如果几乎所有的任务都使用了这些寄存器状态信息,那么延迟状态加载,这个逻辑反而会变成累赘,增大开销。为啥呢?因为上下文切换过程中“按需加载寄存器的判断、执行逻辑”的开销,已经超出了直接加载这些寄存器数据的开销。这种情况下,可以选择禁用这个特性。
直接引入的开销,还包含了一些其他的。比如内核更新统计数据相关的,进程切换时,内核需要更新前一个任务执行的CPU时间;比如,内核需要执行调度算法选择下一个要执行的任务等等。
切换间接引入的开销
间接引入的开销,主要是与cache miss相关的,CPU本身有自己的L1、L2、L3级缓存,对于页式管理还有TLB(转换旁路缓冲),还有分支预测相关的(branch direction, branch target, return buffer),等等。
L1~L3 cache miss
CPU本身的L1、L2、L3级缓存,本身是为了加速数据读写、减少对内存的访问所引入的,如果任务切换后,任务需要读写的数据在CPU cache中没有找到,就要再去读写内存并同步到cache中去,这个是比较耗时间的。另外,如果任务之前在当前CPU core的cache上是有数据的,但是经过几次任务切换后,将其调度到了另外的CPU或CPU core上,那么这个时候任务读写数据时也肯定会出现cache miss,也需要读写内存。这些CPU cache miss的问题会带来明显的开销。
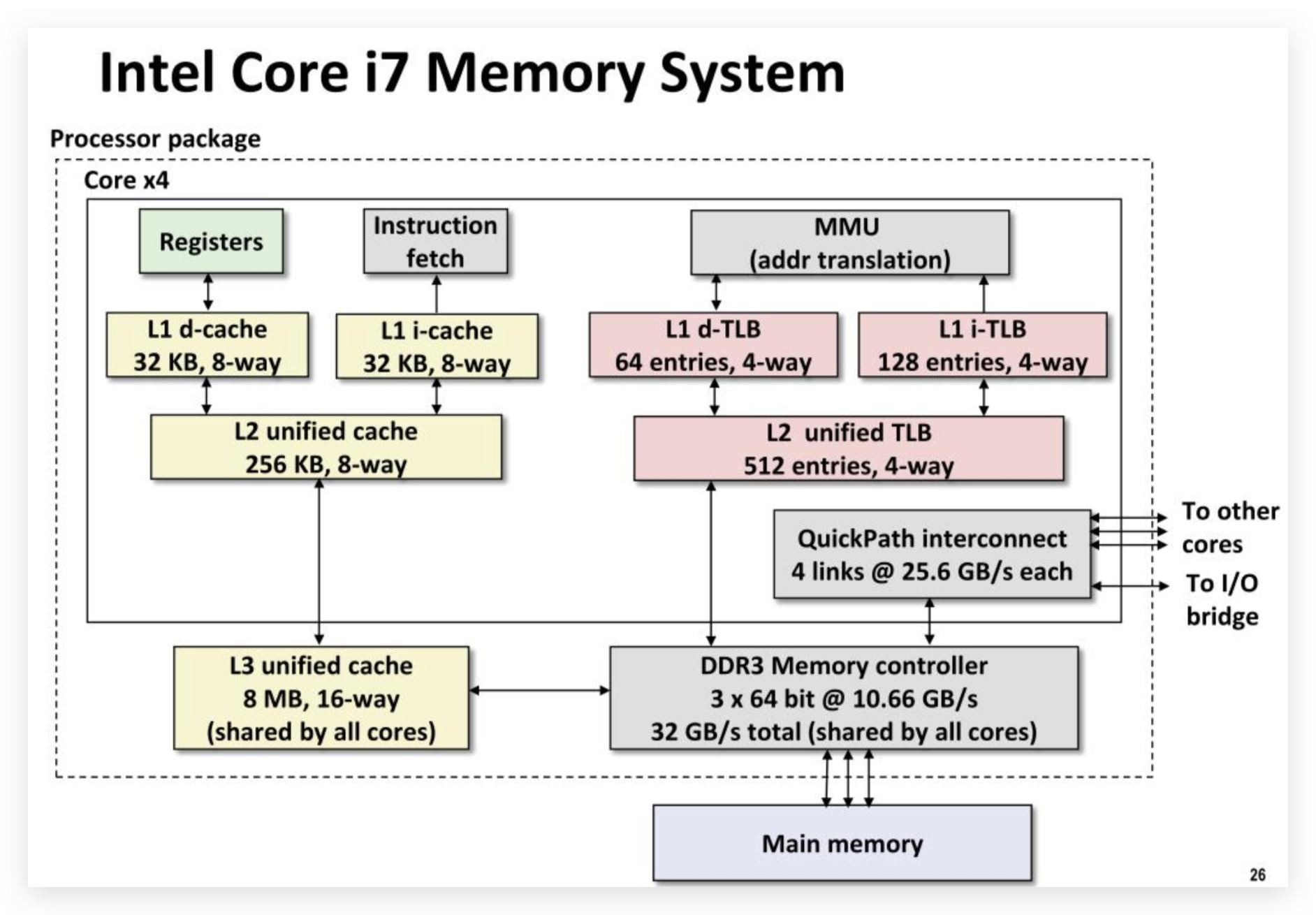
TLB cache miss
操作系统采用页式管理对进程地址空间进行管理,为了节省内存空间,操作系统一般都是采用多级页表的方式,如Linux中采用PGD+PUD+PMD+PTE+Offset的方式,这样以更少的内存占用支持了更大的虚地址空间。但是多级页表也有个问题,计算一个虚地址对应的物理地址需要多次读取内存,也有开销。
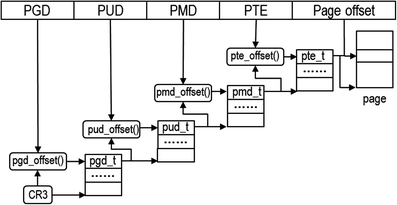
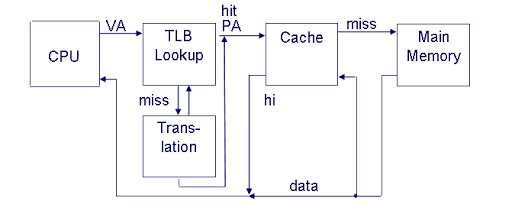
页式管理中很重要的一个操作就是计算虚拟地址向物理地址的映射。对于某些高频访问的内存地址,难道每次都需要计算吗?非也!任何“读写比”很高的场景,都可以考虑通过缓存来解决。页式管理中为此引入了TLB(Translation Lookaside Buffer,转换旁路缓冲)来缓存高频访问的地址映射关系。如果上下文切换导致地址映射时出现了TLB cache miss,那重新计算地址映射所引入的开销也是不可忽视的。
在某些硬件平台上,TLB是有PCID支持的,PCID允许从硬件层面对TLB中的条目进行精细化管理,如淘汰特定的条目。简单说下PCID对TLB cache miss的影响,适当延伸下知识面,更深刻地认识下上下文切换的开销。
TLB没有PCID支持
如果没有PCID支持的话,每次CR3寄存器写操作,都会清空整个TLB,说的再具体点就是执行系统调用、遇到interrupt、exception、trap的时候,都要清空TLB,这也是一种开销。
TLB有PCID支持
PCID本身也是有开销的,具体来说,当在某个CPU上的页式映射出现变化之后,它会使得其他CPU上的页式映射失效,以重建最新的映射。这称为“multi-CPU TLB shootdown”。这个的开销相对来说是比较大的,它会中断其他的CPU,每个被中断的CPU都会引入几百个时钟周期的延迟。如果没有PCID的话,就可以避免上述开销。
举个例子,比如,对于一个单进程单线程程序,它只可能同时在一个CPU core上运行,不可能存在其他CPU同时访问该进程的地址空间,然后也不应该出现导致“multi-CPU TLB shootdown”的情况。禁用PCID就可以避免这种开销。
再举个例子,如果一个单进程多线程的程序,即便他们可能运行在多个CPU core上,但是只要它的地址空间是在相同的NUMA domain,那么只有访问这个NUMA domain的CPU需要参与到“multi-CPU TLB shootdown”的任务中,并不需要所有的CPU都引入这个开销。禁用PCID也可以避免这种开销。
需要具体问题具体分析了,不同的任务场景,需要针对性处理,PCID虽然对于避免整个flush TLB而言会有一定的优化效果,但是我们上面列举的情景下,PCID本身引入的开销已经超过了其带来的收益,反而导致性能更差了。
其他非紧密相关开销
上下文切换时,可能会涉及这样一个场景,如启动一个新线程,甚至启动一个新进程,而新进程、线程的建立和启动,操作系统都是需要做一定的工作的,以进程为例,我们需要从pid名字空间分配一个全局最小pid,需要建立其虚拟内存空间,建立页表,设置其任务上下文并准备调度。这些工作都是有开销的。
本文对上下文开下的量化部分也有对这部分开销做测量,可以关注下新启动一个线程或进程的开销与一般的上下文切换开销的差异。
量化上下文切换开销
量化的复杂性
要想准确地量化上下文切换的开销,就必须要知道这里的开销涉及到哪些类型。前文已经介绍了这里大致包含的开销类型,读者肯定也感受到了量化这一开销的复杂性。
确实,要想量化这里的开销,一方面要考虑具体硬件层面的特性,另一方面也要考虑软件层面的影响,比如系统当时的负载、系统采用的调度器算法(CFS、FIFO等)、任务的优先级,测试程序测量的模拟上下文切换的代码粒度……这些都会影响量化准确性。
针对这一问题,很多系统性能工程师、研究人员进行了探索,可以供我们参考,文末附了部分测量相关的资料、论文,感兴趣的可以查看以了解更多信息。
一种量化的方法
这里只讲述一种只测量上下文切换引入的“直接开销”的方法:

- pipe创建一个管道;
- 创建两个threads,它们通过该pipe实现类似ping-pong操作,每次交还1Byte数据;
- 两个threads通过一个条件变量来同步;
这个例子很好理解,也希望读者能理解这么设计的用意,能足够代表上下文切换场景,又尽量降低其他负载对评估准确性的影响。另外,为了避免任务调度时线程在不同CPU上的迁移带来的影响,还可以考虑CPU affinity,通过taskset将进程绑定到特定的CPU上降低影响。
这里,称这两个线程为read、write线程吧,ping-pong时涉及到read、write线程的上下文切换,反复执行上百万次,然后求平均每次执行耗费的时间,从而近似评估上下文切换的时间。
- 起初,pipe空,条件变量为0,read线程running,write线程wait条件变量=1;
- read线程,写入1B数据,然后更新条件变量=1,自身wait条件变量=0;
- 条件变量更新为1后,唤醒wait的write线程echo数据、更新条件变量=0,wait条件变量=1;
- 条件变量更新为0后,唤醒wait的read线程写数据、更新条件变量=1,wait条件变量=0;
- ...
- 反复执行100w次;
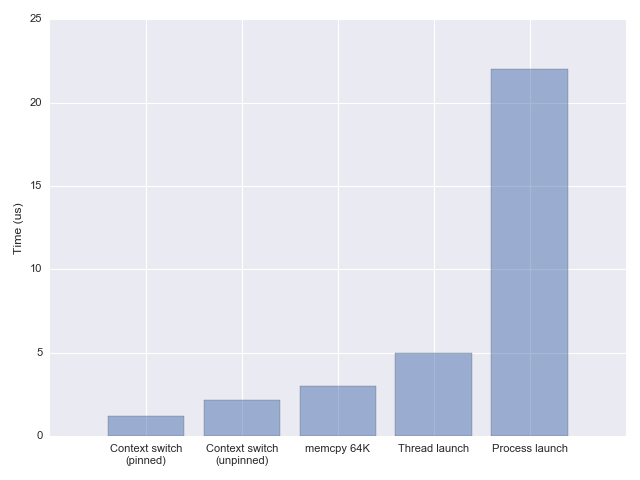
下图是根据上述方法测量的上下文切换的开销。大家可以把拷贝64KB内存数据作为一个参考值,大约为3μs。上下文切换+考虑CPU粘性的情况下,上下文切换耗时大约为1.2μs;上下文切换+不考虑CPU粘性的情况下,这个耗时大约在2.4μs。
量化结果分析
虽然看上去上下文切换的开销只有1.2μs或者2.4μs,但是我们却不能简单认为上下文切换开销低,因为上下文切换可能对应着启动一个线程,或者启动一个进程。启动一个线程的耗时,大约为5μs,启动一个进程则需要22μs左右,开销增长明显。
读者可能会问什么时候会启动一个进程or线程,这不在本篇文章讨论之内,但是可以简单说下。在系统调用、中断、异常、陷阱、timer定时器触发的时候需要涉及到触发任务调度,会不会调度一个不同的任务,需要看内核采用的调度器,不同的调度器有不同的调度策略,比如CFS选择vruntime最小的一个任务进行调度,保证调度的公平,或者deadline保证对响应时间等等。
如上图所示,我们拿一个真实线上机器来看下,vmstat 1 输出信息中列cs表示上下文切换次数,我们可以观察到不同任务的上下文切换次数。
前面展示的量化方法中提及一次上下文切换时间最快为1.2微秒(线程+CPU亲和性),我们姑且认为这个结果可信,我们来考虑下这1.2微秒内能发生什么。
1.2μs意味着什么
1.2μs意味着什么呢?从人对时间的感受cd 而言,这个时间粒度很短,短到可以忽略不计,但是从微观上来讲,这段时间足够执行很多条机器指令了。
我们应该充分压榨利用计算资源,在这1.2μs内输出更大的价值。所要做的就是在1.2μs内尽可能执行更多指令,而不是在这里执行“无谓的”上下文切换。
对于CPU而言,CPI(平均指令时钟周期数)可以描述超标量流水线计算机执行指令时的并行情况如何。再就是IPS,表示每秒可以执行的指令数量。维基百科对不同处理器型号的效率进行了统计,详见:https://en.wikipedia.org/wiki/Instructions_per_second#:~:text=Instructions%20per%20second%20(IPS)%20is,IPS%20measurement%20can%20be%20problematic.
可见图中处理器Intel Core i7 920 (4-core) 工作在8.93GHz下,每秒约执行82300 MIPS(百万)条指令,那1.2微秒也就相当于可以执行82300条指令,天呐,一次上下文切换的时间竟然能够执行82300条指令啦。即使上下文切换不能避免,也应该尽量减少上下文切换的开销。
减少上下文切换开销
精简上下文数据
在表示一个用户态协程上下文时,并不是处理器中所有寄存器都会用到,所以就可以对ucontext_t中那些没用的寄存器进行阉割,以降低处理器读写内存时的延时。
考虑CPU亲和性
考虑CPU亲和性,任务切换时尽量将任务切换回原来执行的CPU核心上,以减少CPU cache miss的几率。
其他可行方法
应该也有一些其他的方法用来减少上下文切换的开销,特别是上下切换间接引入的部分,比如前面提及的PCID对TLB的精细化管理,等等,这可能跟操作系统、硬件都有关系了。
考虑下协程切换
前面我们介绍了上下文切换的开销类型,介绍了一种量化上下文开销的方法,并看到了大致的一个上下文切换的结果数据,有了一点直观的感受。然后我们提及了几种可行的减少上下文切换开销的可行方法。
现在是时候认真考虑下协程相关的问题了,我们也已经知道,协程相对进程、线程会更加轻量,包括其初始栈内存大小、上下文信息、创建销毁速度,等等。那不禁要问,协程的上下文是长什么样子,和进程、线程有什么差别呢?
以go语言为例,goroutine上下文切换的成本很低,goroutine上下文切换仅涉及三个寄存器(PC、SP、DX)的修改,那线程呢?线程的上下文切换需要包括模式切换(从用户模式切换到内核模式) 和PC、SP等16个寄存器的修改。开销谁大谁小一看便知。
参考资料
- what is the overhead of a context switch, https://stackoverflow.com/questions/21887797/what-is-the-overhead-of-a-context-switch/54057079#54057079
- linux kernel documentation, https://sourcegraph.com/github.com/torvalds/linux/-/blob/Documentation/x86/pti.rst#L116
- quantifying the cost of context switch, https://www.usenix.org/legacy/events/expcs07/papers/2-li.pdf
- measuring context switching and memory overheads for linux threads, https://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/
- thread overhead, https://github.com/eliben/code-for-blog/tree/master/2018/threadoverhead
- user-level threads...with threads, Paul Turner, Google, https://www.youtube.com/watch?v=KXuZi9aeGTw&feature=youtu.be
- 超标量处理器流水线,https://zhuanlan.zhihu.com/p/195008675
- instruction per second,https://en.wikipedia.org/wiki/Instructions_per_second#:~:text=Instructions%20per%20second%20(IPS)%20is,IPS%20measurement%20can%20be%20problematic.
- how long does it take to make context, https://blog.tsunanet.net/2010/11/how-long-does-it-take-to-make-context.html
- why go so fast, https://morioh.com/p/36af32e3f52c****